Learning 4D Action Feature Models for Arbitrary View Action Recognition
Pinkgun Yan and Saad Khan.In this paper we present a novel approach using a 4D (x,y,z,t) action feature model (4D-AFM) for recognizing actions from arbitrary views. The 4D-AFM elegantly encodes shape and motion of actors observed from multiple views. The modeling process starts with reconstructing 3D visual hulls of actors at each time instant. Spatiotemporal action features are then computed in each view by analyzing the differential geometric properties of spatio-temporal volumes (3D STVs) generated by concatenating the actors silhouette over the course of the action (x,y,t). These features are mapped to the sequence of 3D visual hulls over time (4D) to build the initial 4D-AFM. To generalize the model for action category recognition, the AFMs are further learned over a number of supplemental videos with unknown camera parameters. Actions are recognized based on the scores of matching action features from the input videos to the model points of 4D-AFMs by exploiting pairwise interactions of features. Promising recognition results have been demonstrated on the multi-view IXMAS dataset using both single and multi-view input videos.
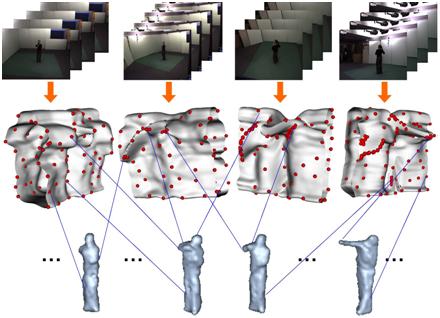
Pingkun Yan, Saad M. Khan, and Mubarak Shah, Learning 4D Action Feature Models for Arbitrary View Action Recognition, IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska 2008.