
Mikel Rodriguez, Mubarak Shah
Our method begins by learning a set of posture clusters which are used to initialize segmentation. Additionally, we learn a codebook of local shape distributions based on humans in the training set. When the system is presented with a testing video sequence, it extracts contours from the foreground blobs in each frame, samples them using shape context, finds instances of the learned local shape codebook, and casts votes for human locations and their respective postures in the frame. Subsequently, the system searches for consistent hypotheses by finding maxima within the voting space. Given the locations and postures of humans in the scene, the method proceeds to segment each subject. This is achieved by placing the characteristic silhouette corresponding to the posture cluster of every consistent hypothesis around the centroid vote.
Given a a set of training video sequences, we perform background subtraction and extract silhouettes by performing edge detection on foreground blobs corresponding to humans in the scene. Each silhouette is represented using shape context descriptors. Silhouettes are clustered using K-means.

Once the posture clusters are created the second phase of the process consists of learning a codebook of local shapes and their spatial distribution for different poses and scales. We then learn the spatial distribution of the codebook entries for different postures. This is done by iterating through all of the foreground blobs from the training set, sampling each silhouette via shape context descriptors, and matching these against codebook entries. For each instance of a codebook entry we record two pieces of information: The position with respect to the centroid of the human silhouette on which it occurred, and the closest posture cluster to which the silhouette belongs.
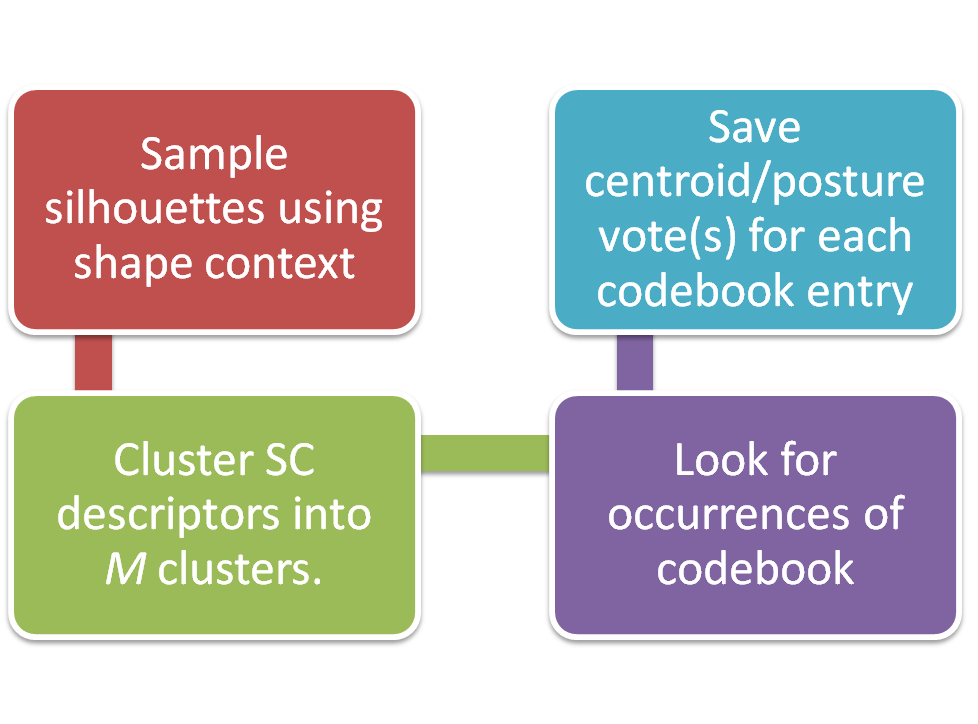
Given a testing video sequence we sample the silhouettes which are extracted from the foreground blobs produced by background subtraction. These samples are then compared to the learned codebook of local shapes. If a match is found, the corresponding codebook entry casts votes for the possible centroid of a human in the scene and a posture cluster to which it belongs. Votes are aggregated in a continuous voting space and Mean-Shift is used to and maximums.

We evaluated the performance our system for detecting and segmenting humans on a set of challenging video sequences containing significant amounts of partial occlusion.
Furthermore, the videos included in the testing procedure featured humans performing a diverse set of activities within diferent contexts, such as walking on a busy city street, running a marathon, playing soccer, and participating in a crowded festival. Our training set ranged from 700 to 1,100 frames from the various video sequences containing human samples. Meta-data in the training set included the centroid of each silhouette, along with the posture cluster to which it belonged. Our testing database consisted of a wide range of scenes, totaling 34,100 frames in size and contained a total of 312 humans for which the torso is visible. The size of the humans across the video sequences averaged 22x52 pixels. Figure 5 shows some examples from the data set.
