KEYS - Incremental Action Recognition Using Feature-Tree
- Introduction
- Proposed Method
- Algorithm
- SR-Tree
- Advantages
- Experiments and Results
- Related Publication
Introduction
Human action recognition has been one of the most challenging problems studied over the last two decades for reliable and effective solutions. Most current approaches suffer from many drawbacks in practice, which include(1) The inability to cope with incremental recognition problems.
(2) The requirement of an intensive training stage to obtain good performance.
(3) The inability to recognize simultaneous multiple actions.
(4) Difficulty in performing recognition frame by frame.
In order to overcome all these drawbacks using a single method, we propose a novel framework involving the feature-tree to index large scale motion features using Sphere/Rectangle-tree (SR-tree). The recognition consists of two steps: 1) recognizing the local features by non-parametric nearest neighbor (NN), 2) using a simple voting strategy to label the action. The proposed method can provide the localization of the action. Since our method does not require feature quantization, the feature-tree can be efficiently grown by adding features from new training examples of actions or categories. Our method provides an effective way for practical incremental action recognition. Furthermore, it can handle large scale datasets due to the fact that the SR-tree is a disk-based data structure. We have tested our approach on two publicly available datasets, the KTH and the IXMAS multi-view datasets, and obtained promising results.
Proposed Method
Figure 1 shows the main steps in our method for action recognition using feature tree. There are two phases: Figure 1 (a) depicts the procedure of construction of the feature-tree and Figure 1 (b) describes the recognition steps. In the feature-tree construction stage, local spatiotemporal features are detected and extracted from each labeled video, and then each feature is represented by a pair [d,l] where d is the feature descriptor and l is the class label of the feature. Finally, we index all the labeled features using SR-tree. In the recognition stage, given an unknown action video, we first detect and extract local spatiotemporal features, and then for each feature we launch a query into the feature-tree. A set of nearest neighbor features and their corresponding labels are returned for each feature. Each returned nearest neighbor votes for its label. This process is repeated for each feature, and these votes can be weighted based on the importance of each nearest neighbor. Finally, a video is assigned a label, which receives the most votes. The entire procedure does not require intensive training. Therefore, we can easily apply incremental action recognition using the feature-tree. Besides, we also can easily localize the actions in the video, and detect multiple actions occurring simultaneously in the same video.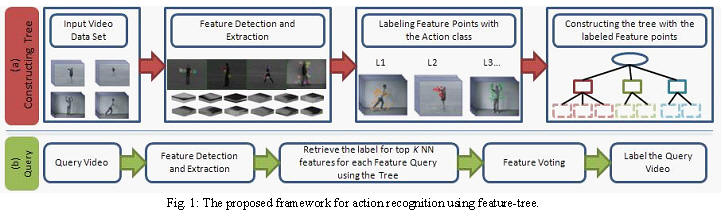
Algorithm
Feature Extraction
In order to detect an action in a given video, we use the spatiotemporal interest point detector proposed by Dollar et al.. Compared to the 3D Harris-Corner detector, it produces dense features that can significantly improve the recognition performance in most cases. This detector utilizes 2-D Gaussian filter and 1-D Gabor filter separately in spatial and temporal directions respectively. A response value is given by the following function at every position (x, y, t):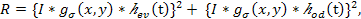
where
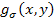 is the spatial Gaussian filter,
and
is the spatial Gaussian filter,
and 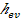 and
and 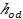 are a quadrature pair of the 1-D
Gabor filter in time. It produces high responses to the temporal intensity change points. N interest points are selected
at the locations of local maximal responses, and 3D cuboids are extracted around them. For simplicity, we used the flat
gradient vectors
are a quadrature pair of the 1-D
Gabor filter in time. It produces high responses to the temporal intensity change points. N interest points are selected
at the locations of local maximal responses, and 3D cuboids are extracted around them. For simplicity, we used the flat
gradient vectors 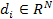 to describe the
cuboids, and utilized PCA to reduce the descriptor dimension, so a video is represented by a set of cuboids
to describe the
cuboids, and utilized PCA to reduce the descriptor dimension, so a video is represented by a set of cuboids
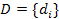 .
.Constructing Feature-Tree
Given a set of action videos V = {v1, v2,…,vM} and its corresponding class label li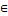 {1,2,…,C}, we extract n spatiotemporal features
{1,2,…,C}, we extract n spatiotemporal features
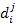 (1≤j≤n) from video vi. We associate
each feature with its class label and get a two-elements feature tuple
(1≤j≤n) from video vi. We associate
each feature with its class label and get a two-elements feature tuple 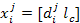 .
Then we obtain a collection of labeled features T = {
.
Then we obtain a collection of labeled features T = {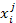 }
to construct our feature-tree. We use SR-Tree for feature-tree construction which is explained later.
}
to construct our feature-tree. We use SR-Tree for feature-tree construction which is explained later.Action Recognition
Given the feature-tree constructed during the training, the action recognition starts by extracting spatiotemporal features from an unknown action video. Suppose the query action video is represented by a set of spatiotemporal features, say Q = {dq} (1≤q≤M), our recognition task is to find its class label. Instead of using a complicated learning method, we adopt simple voting schema.For each query feature dq, we retrieve the labels of the K nearest neighbors from the feature-tree, and assign it a class label based on the votes of the labels of the K returned features. Then, the label of Q is decided by the final voting of the class labels of the query features in Q. Note that, generally the query features of Q may contain good and bad features (good feature meaning discriminative features). In order to distinguish the votes from them, we can assign a class label to Q using the following equation:
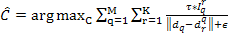 (1)
where
(1)
where 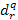
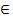 NN(dq),
NN(dq),
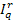 is an indicator function which is equal to 1 if the label of dr is
C, is zero otherwise, and
is an indicator function which is equal to 1 if the label of dr is
C, is zero otherwise, and 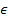 ,
, 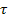 are constant numbers (NN - Nearest Neighbor). Therefore,
the contribution of each feature also depends on how well it matches the query feature.
Noisy features (bad features) usually do not have good matches.
are constant numbers (NN - Nearest Neighbor). Therefore,
the contribution of each feature also depends on how well it matches the query feature.
Noisy features (bad features) usually do not have good matches.The nearest neighbor search algorithm implements an ordered depth first traversal. First, it collects the candidate set, and secondly it revises the candidate set by visiting each leaf having its region intersected with the candidate set. The search is terminated if there are no more leaves to visit and the final candidate set is the search result. The search is performed by computing the distance of the search point
to the region of the child and visiting the child which is closer. Since the region
for an SR-tree is the intersection of a bounding sphere and a bounding rectangle, the
minimum distance from a search point to a region is defined as the maximum between the
minimum distance to the bounding sphere and the minimum distance to the bounding
rectangle. We summarize the nearest search procedure and the action recognition steps
in Table 1 and Table 2.