Independently Moving Objects Detection in Non-planar Scenes using Multi-Frame Monocular Epipolar Constraint
- Related Publications
- Problem Definition and Overview
- Proposed Method
- Advantages over Fundamental Matrix
- Experiments and Results
- References
Related Publications
"Detection of Independently Moving Objects in Non-planar Scenes via Multi-Frame Monocular Epipolar Constraint".
Soumyabrata Dey, Vladimir Reilly, Imran Saleemi and Mubarak Shah
ECCV 2012. [PDF]
Problem Definition and Overview
In this paper we present a novel approach for detection of independently moving foreground objects in non-planar scenes captured by a moving camera. We avoid the traditional assumptions that the stationary background of the scene is planar, or that it can be approximated by dominant single or multiple planes, or that the camera used to capture the video is orthographic. Instead we utilize a multiframe monocular epipolar constraint of camera motion derived for monocular moving cameras defined by an evolving epipolar plane between the moving camera center and 3D scene points.Proposed Method
The steps of our method for detecting moving objects from a video captured by a moving camera in a non planer scene is shown in the next figure. The purpose of our paper is to present a novel method for segmenting moving objects, in a video captured by a generally moving camera, observing a non-planar 3D scene. We capture frame by frame optical flow for the whole video. Then we divide the video into multiple fixed set of frames and for each set of frames perform particle advection. The resulting set of particle trajectories contains two subsets. In the first subset the motion of the particles was induced purely by the motion of the camera (this is a set of particles belonging to stationary background in the world). In the second subset, the trajectories combine the motion of the camera, as well as the motion of independently moving objects. We separate the two sets using the constraint, defined by the proposed Multiframe Monocular Fundamental Matrix (MMFM). We define this constraint as the evolution of the camera model with time, relative to some initial camera position. The evolving camera model defines an evolving epipolar plane between the initial center of the camera, its subsequent centers, and the static scene point. This multi-frame epipolar constraint can then be expressed as a dynamically changing fundamental matrix. When we assume that the evolution of camera parameters can be represented by polynomial functions of time, this monocular multiframe fundamental matrix can then also be represented as a polynomial function under assumption that the inter-frame camera rotation is small. Thus, we can obtain the coefficients of this matrix for frame segments of length N and use them to determine whether particle advection trajectories belong to moving or static objects.
 |
| |
Advantages over Fundamental Matrix
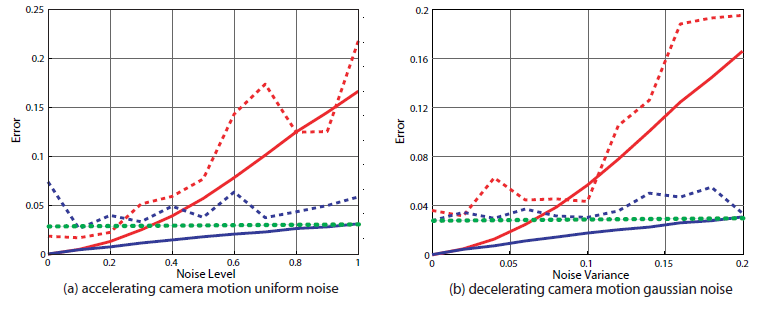
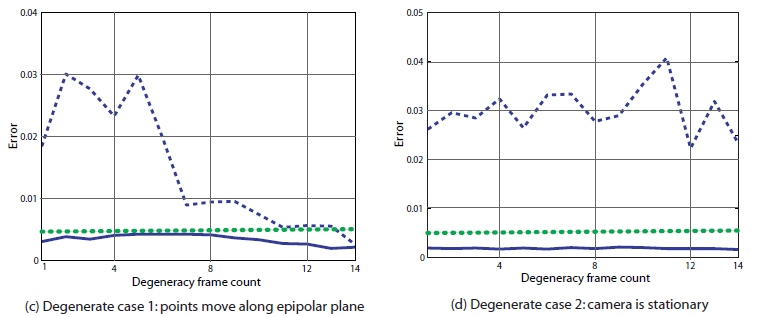
In theory, one can compute a regular fundamental matrix between some frame pairs, compute the error of the points, and average the result for the trajectory. However, in order for fundamental matrix to work properly, the frames must have a wide baseline. Since the motion of the camera is unknown, it is not clear between which frames the fundamental matrix should be computed. Any temporal distance that is selected between the frames will work for some pairs but not for others depending on the motion of the camera. For example one can try to use a floating baseline by computing a fundamental matrix between frames (1, t), varying t from 2 to N, where N is the number of frames. However, if the camera is accelerating from low initial velocity, the initial frame pairs (1,2), (1,3), may have a baseline that is too narrow, resulting in poor matrix estimation and motion segmentation. By contrast, the MMFM will properly capture the evolution of the motion of the camera, and be able to correctly segment out the moving objects.We have performed a set of synthetic experiments using the fundamental matrix approach and our proposed method. The following figure show the results of the experiments. For the experiments, we have used synthetic data consisting of 1000 static points and 10 randomly moving points. The points are randomly distributed through space in front of a moving camera, they are imaged, and random (sub figure (a)) or gaussian (sub figure (b)) noise is added to their images. The figure shows error values between moving points (dashed lines) and static points (solid lines). Red curves are for regular fundamental matrix, while blue curves are for our proposed constraint. The dotted green line indicates an error threshold. Sub-figures (a) and (b) show the scenarios when camera accelerate and decelerate respectively. As can be seen from the figure, when MMFM is used there is a clear separation between the errors of moving and static points for a wide range of noise. By contrast, in the case of regular fundamental matrix, any given threshold works only for a narrow range of noise. Sub-figures (c) and (d) respectively illustrates the performance of MMFM model under the degenerate cases when points move along the epipolar plane and when camera remains stationary. Note, MMFM needs a number of frames to model the camera motion. In our case, we use 15 frames to compute MMFM. The x axis of the sub-figures (c) and (d) indicates the number of frames (among the frames used for MMFM computation) for which degenerate condition holds.
Experiments and Results
To validate our proposed method we performed extensive set of experiments on a diverse set of video sequences captured from moving cameras (aerial, and hand held) and in presence of large out of plane objects. The seq1 - seq5 are our sequences where cars3 - cars7 and cars9 are from JHU 155 dataset. We compared the performance of our method with homography based background subtraction method, rank constraint trajectory pruning method of Sheikh [1] et. al, and a method based on the regular fundamental matrix constraints. To compute the quantitative performance, first we obtained the ground truth for all sequences used in our experiments by manually selecting a silhouette around each moving object of each frame. We then compared the detection results of the methods mentioned above, as well as the proposed method with the ground truth. In order to quantify the performance, we used measures similar to VACE performance measures [2], which are area based measures which penalize false detections as well as missed detections. Accuracy of detection, called frame detection accuracy (FDA), is estimated as the ratio of the intersection of detection and ground truth patches and union of detection and ground truth patches. All the detected patches in a frame which cannot be mapped with any of the groundtruth objects are classified as false detections and a measure of per frame false detection called Frame False Detection Ratio (FFDR) is computed as the ratio of all the false detection patches and all the detection patches. Sequence Frame Detection Accuracy (SFDA) and Sequence Frame False Detection Ratio (SFFDR) are respectively the summations of FDA and FFDR for all the frames.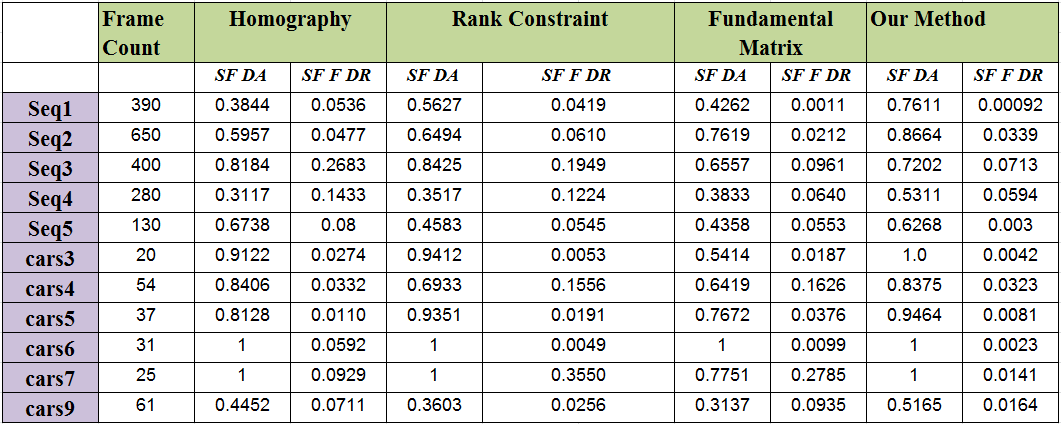
References
"Background subtraction for freely moving cameras".
Yaser Sheikh, Omar Javed and Takeo Kanade
ICCV 2009.
"Framework for performance evaluation of face, text, and vehicle detection and tracking in video: Data, metrics, and protocol".
Yaser Sheikh, Omar Javed and Takeo Kanade
PAMI 31(2) (2009) 319-336.
#####################################################