Arslan
Basharat,
Yun Zhai, and
Mubarak Shah,
Content Based
Video Matching Using Spatiotemporal Volumes, Journal of Computer
Vision and Image Understanding (CVIU), Volume 110, Issue 3, June
2008, Pages 360-377, Similarity Matching in Computer Vision and Multimedia
NOTE: All
videos have been encoded using
DIVX codec.
Abstract
This paper presents a novel
framework for matching video sequences using the spatiotemporal segmentation of
videos. Instead of using appearance features for region correspondence across
frames, we use interest point trajectories to generate video volumes. Point
trajectories, which are generated using the SIFT operator, are clustered to form
motion segments by analyzing their motion and spatial properties. The temporal
correspondence between the estimated motion segments is then established based
on most common SIFT correspondences. A two pass correspondence algorithm is used
to handle splitting and merging regions. Spatiotemporal volumes are extracted
using the consistently tracked motion segments. Next, a set of features
including color, texture, motion, and SIFT descriptors are extracted to
represent a volume. We employ an Earth Mover’s Distance (EMD) based approach for
the comparison of volume features. Given two videos, a bipartite graph is
constructed by modeling the volumes as vertices and their similarities as edge
weights. Maximum matching of this graph produces volume correspondences between
the videos, and these volume matching scores are used to compute the final video
matching score. Experiments for video retrieval were performed on a variety of
videos obtained from different sources including BBC Motion Gallery and
promising results were achieved. We present qualitative and quantitative
analysis of retrieval along with a comparison with two baseline methods.
Main Steps
Spatiotemporal Volume
Extraction
Give a video, we are able to extract meaningful
regions that correspond to moving foreground and background "objects". Following
are the main steps performed to extract volumes from a video.
Trajectory Generation
Given a video perform following steps to
extract SIFT interest point trajectories:
Computation of SIFT
interest point correspondence between neighboring frames,
Initial trajectory
generation by merging point correspondences,
Removal of irregular
trajectory segments,
Merging broken
trajectories,
Removal of small
trajectories.
Region Detection
Different motion segments
(color coded) are determined using homography based motion segmentation. The
proximity of interest points within a segmented region are used to group of
points belonging to different objects. This video shows results of initial
region detection along with trajectories generated in the previous step. The
changing colors show that there is no correspondence information at
this stage.
Region Tracking
Tracking performed using the
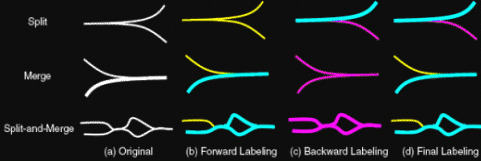
maximum trajectory membership constraint between detected regions. Figure
illustrates the effect of the two pass tracking algorithm used on three
scenarios of objects splitting and merging. (a) Types of relative motion of
two segments in a video. (b) Forward labeling generates first set of labels
by progressing the labels from the first to the last frame of the video. (c)
Backward labeling is applied in the reverse direction to produce another set
of labels. (d) Two sets of labels are merged to produce the final labels.
Volume Extraction
Spatiotemporal volumes are
finally extracted by simply stacking together the tracked bounding boxes.
Each row contains three sample frames from the video along with the
extracted volume. Each bounding box represents one of the several regions
being tracked in each video. The consistent color of the bounding box
represents the accuracy of region tracking. We are also able to handle split
and merge in case of two regions belonging to the airplane (second frame).
Both of these regions (with same yellow label) contribute to the airplane
volume shown on the extreme right.
Feature Extraction
Features extracted from each spatiotemporal
volume include:
Interest point descriptors
Color
Texture
Motion
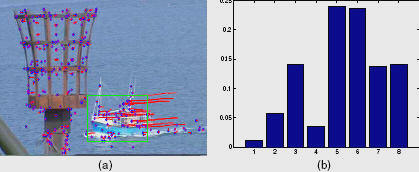
Motion of a volume is captured by
eight quantized directions of motion of the member trajectories. (a) Rectangle
captures a boat moving towards bottom left in the video. (b) The peaks
correspond to left and bottom directions (pi to 3pi/2 out of [0, 2pi] range).
Interest point trajectories are shown in red with blue end points.
Isodata clustering is performed in the feature
space to generate respective feature descriptor. For instance, in case of the
SIFT interest point descriptor, 128-dimensional space is used to generate a set
of clusters. This set of clusters is generate signature representation
which includes respective mean features and cluster population for each cluster.
Feature Comparison and Video
Matching
Earth Mover's Distance is used to
match two signatures of the same feature coming from two volumes from two
different videos. For a particular feature, the similarity measure between two
volumes is given by
which is used as the edge weight
between the two volumes in our graphical representation of the videos as
illustrated here:
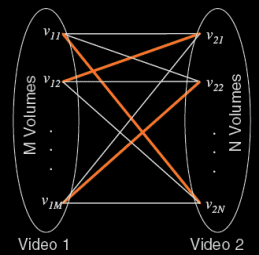
A bipartite graph is constructed
with volumes as the vertices and their feature similarities as edge weights. The
maximum matches in this bipartite graph provide the volume correspondence
between two videos. The highlighted edges represent the correspondences. Mean of
the correspondence values gives the final matching score between the two videos.
Results
A snapshot of our dataset that
includes 337 videos comprising of 74 boat, 80 car, 148 airplanes, and 35 tank
videos. The significant variation in the object appearance within each category
makes this dataset very challenging.
Video Matching for Retrieval
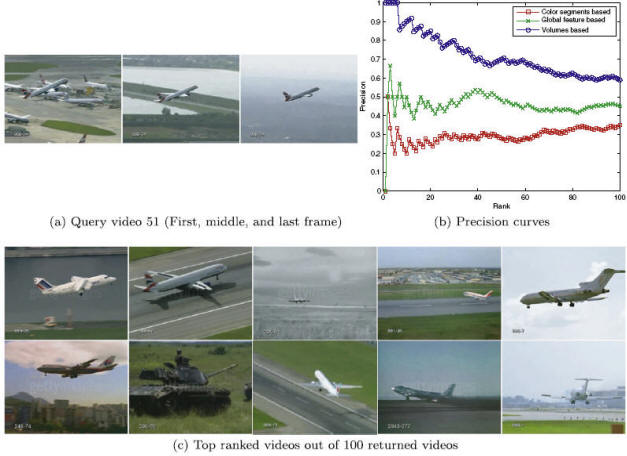
Video retrieval result. (a) Frames of the input
query video. (b) A comparison of performance against two other approaches which
are based on keyframes. The proposed volume based (blue) method produces higher
precision values. (c) Keyframes of the top 10 similar videos out of the 100
retrieved videos.
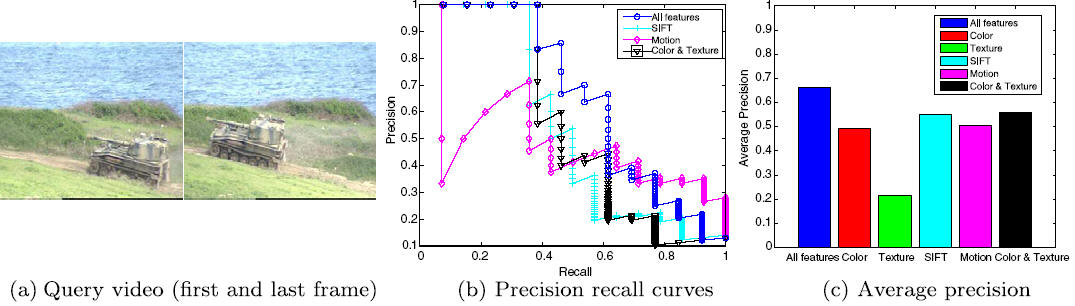
Choosing the right features
This
figure presents the effects of different combinations of features on the quality
of retrieval for the query video. Several combinations can be chosen based on
different weights of these features. It was found that the best performance is
achieved using a combination of all the volume based features.