Complex Events Detection using Data-driven Concepts
Introduction
Automatic event detection in a large collection of unconstrained videos is a challenging and important task. The key issue is to describe long complex video with high level semantic descriptors, which should find the regularity of events in the same category while distinguish those from different categories. Common approaches in event detection rely on hand-crafted low level features such as SIFT, STIP, MFCC, and human-defined high level concepts. The use of high level semantic concepts have been proven effective in representing complex events. However, how to discover a powerful set of semantic concepts is still unclear and has not been investigated in previous works. The drawbacks of human defined concepts include:(1) it's hard to extend these concepts to a larger scale
(2) they can not handle multiple modalities
(3) the concepts don't generalize well to new datasets

Fig. 1: Randomly selected example videos from our dataset. Each row shows
frames of four videos from two categories.
In order to overcome all these drawbacks mentioned above, this work proposes a novel unsupervised approach to discover data-driven concepts from multi-modality signals (audio, scene and motion) to describe high level semantics of videos. Our methods consists of three main components: we first learn the low-level features separately from three modalities. Secondly we discover the data-driven concepts based on the statistics of learned features mapped to a low dimensional space using deep belief nets (DBNs). Finally, a compact and robust sparse representation is learned to jointly model the concepts from all three modalities.
Proposed Method
Figure 2 shows the main steps in our method for complex event detection using data-driven concepts. Each video is divided into short clips. We first learn low level features for each modality using Topography Independent Component Analysis (TICA). Then we map our low level features to more compact representations using deep belief networks (DBN). After that, our data-driven concepts are learned by clustering the training data in a low-dimensional space using vector quantization (VQ). Finally, we merge the concepts from three different modalities by learning compact sparse representations.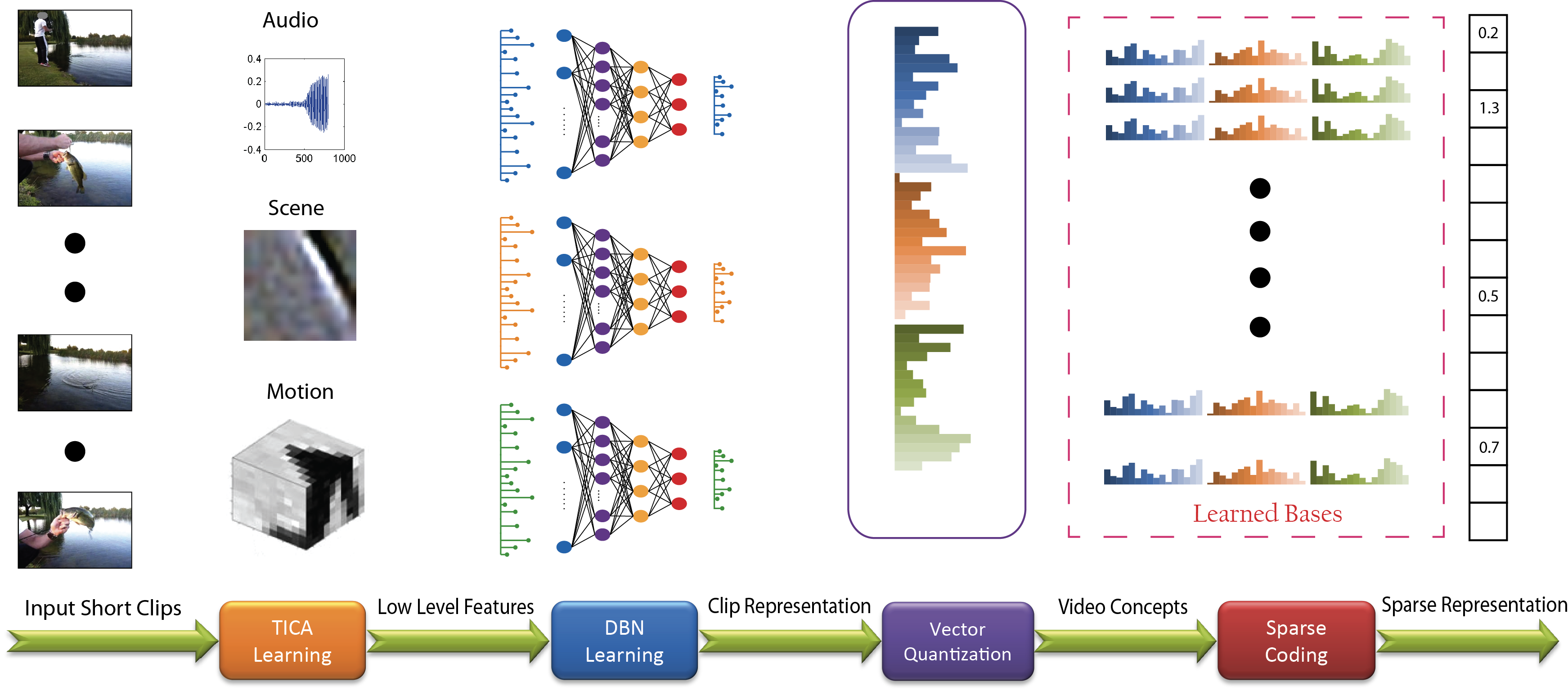
Fig. 2: Flowchart of the proposed method.
Algorithm
Feature Extraction
Considering the data we have are quite diverse and huge amount, we argue that learning good features directly from the data is very efficient. We choose TICA as our low-level building block because of its two advantages: feature robustness and less computational complexity. It learns the invariant audio, scene and motion features from 1D audio signal, 2D image patches and 3D video cuboids respectively. Some of the learned filters are shown in figure 3,4,5.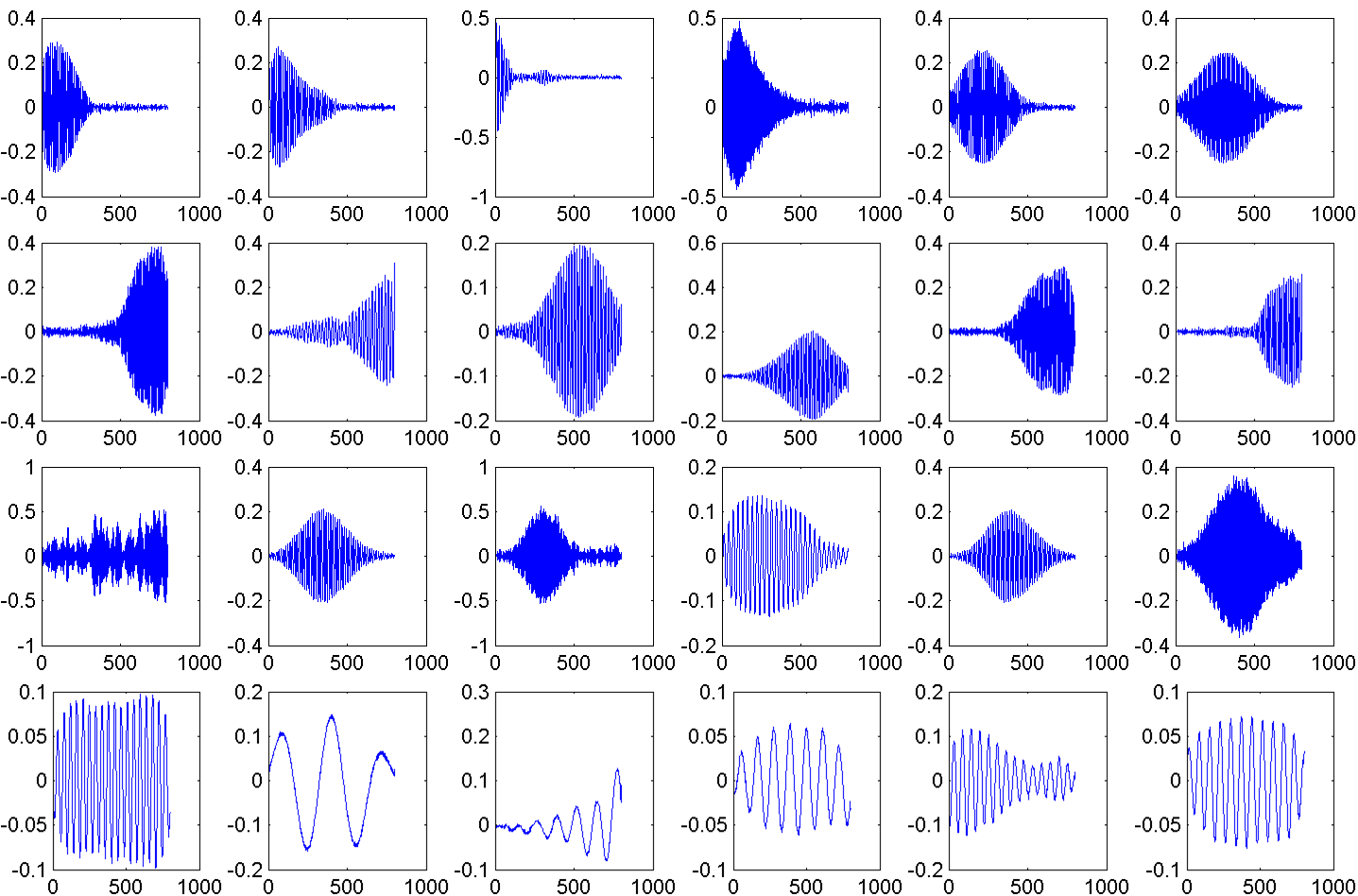
Fig. 3: 24 out of 600 audio filters learned from TRECVID event collection.

Fig. 4: 48 out of 600 image (2D) filters learned from TRECVID event collection.

Fig. 5: 12 out of 600 spatiotemporal (3D) filters learned from TRECVID event collection.
Data-driven Concept Discovery
After learning the low level features from three modalities, we use kmeans to quantize them into word, so then each clip can be represented as a histogram using the traditional bag of word method. We assume there is only one type concept from each of the three modalities appears in a single shot clip. The concepts are the intermediate representation of complex events, and traditional way is to manually annotated the concepts. Here, we propose to use deep belief net to unsupervised learn the concepts from the data. It can learn unlimited number of concepts without manual annotation. It can also expose the low-dimensional structure progressively while preserving the original distribution in a generative manner. In our task, given the clip histogram representations, we stack several layers of rbm, train it layer-wised from bottom to top, and the output of lower layer serve as the input of the upper layer. The final output is the dimensionality reduced compact representation for the clips. Therefore, the clips can be clustered into data-driven concepts using the new compact representations.Event Representation Learning
It is common that concepts of different modalities are highly correlated with each other. For example, in a birthday party event, action concept `people dancing' is almost always co-occur with concept `happy music' or scene concept `crowd people', instead of `horrible music' nor `traffic scene'. By modeling the interaction context and inter-modality occurrence of concepts, we can removing noisy concepts and further improve the event representation. The idea is that we want to learn a set of bases which capture the co-occurrence information of concepts and the event can be represented as a linear combination of the bases. Further, by imposing the sparsity on the coefficients, the noisy occurrence of irrelevant concepts will be removed.Experiments and Results
We tested our approach on TRECVID 2011 event collection, which has 15 categories: "Boarding trick", "Flash mob", "Feeding animal", "Landing fish", "Wedding", "Woodworking project", "Birthday party", "Changing tire", "Vehicle unstuck", "Grooming animal", "Making sandwich", "Parade", "Parkour", "Repairing appliance", "Sewing project". It is a new set of videos characterized by a high degree of diversity in content, style, production qualities, collection devices, language, etc. We also manually defined and annotated an action concept data set based on TRECVID event collection, which has 62 action concepts(e.g. open box, person cheering, animal approaching, wheel rotating, etc.) for approximately 9,000 videos. Table 1 shows our learned features performance compare with other hand-designed features on three datasets. Figure 6 shows our proposed method performance compare with the traditional baseline method.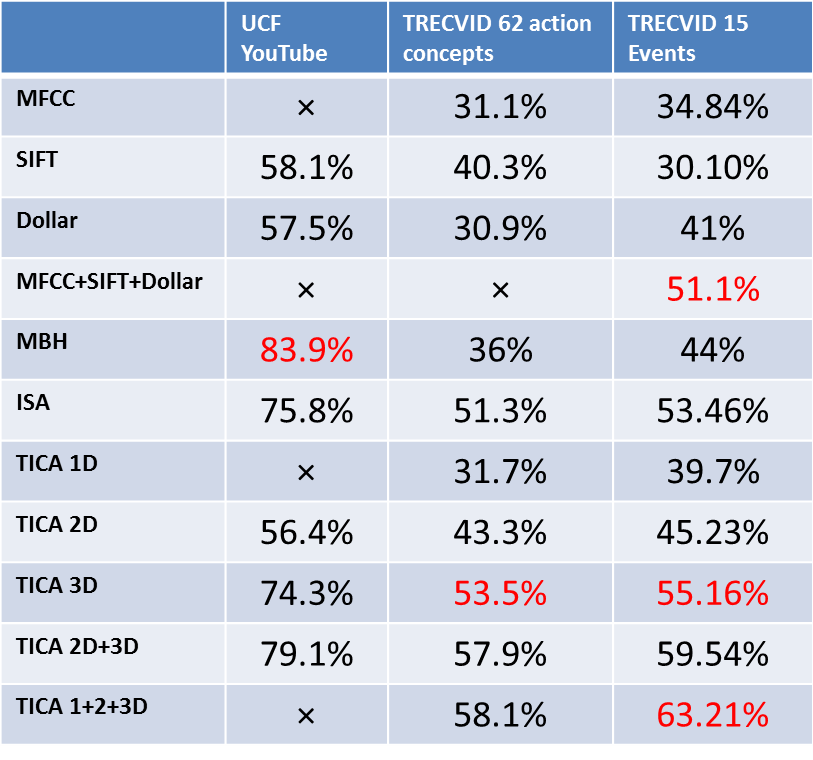
Tab. 1: A comparison of performance using different features and modality combinations.
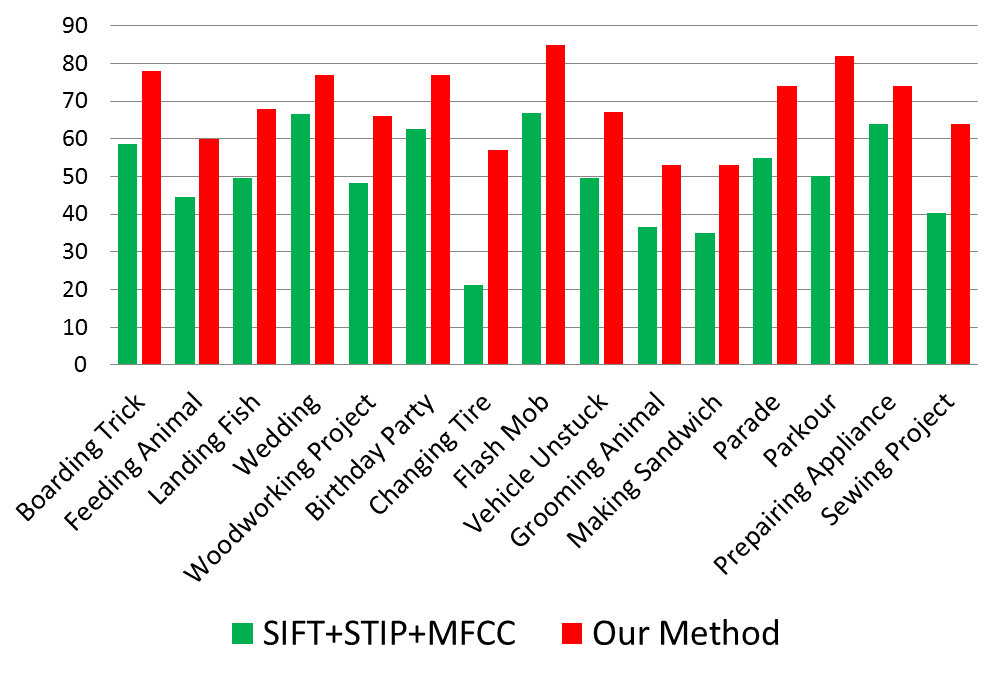
Fig. 6: Comparison of our proposed method with the combination of MFCC, SIFT and STIP features in terms of detection accuracy on each event category.