Classifying Web Videos using a Global Video Descriptor
- Introduction
- Gist of a Video
- Generating Descriptor
- Experimental Results
- Related Publication
- YouTube Presentation
Introduction

Figure 1. Example action classes from the (a) KTH, (b) UCF50 and (c) HMDB51 datasets.
Gist of a Video
Videos which involve similar actions tend to have similar scene structure and motion. The regularities in the appearance or motion can be used to pinpoint the type of actions involved in the video, and can be useful in the classification of videos. The frequency spectrum computed for a video clip could capture both scene and motion information effectively, as it represents the signal as a sum of many individual frequency components. In a video clip, the frequency spectrum can be estimated by computing the 3-D Discrete Fourier Transform (DFT). The motion in a video can be explained in a straightforward way by considering the problem in the Fourier domain. The frequency spectrum of a two-dimensional pattern translating on an image plane lies on a plane, the orientation of which depends on the velocity of the pattern. Furthermore, multiple objects with different motion will generate frequency components in multiple planes as depicted in Figure 2.
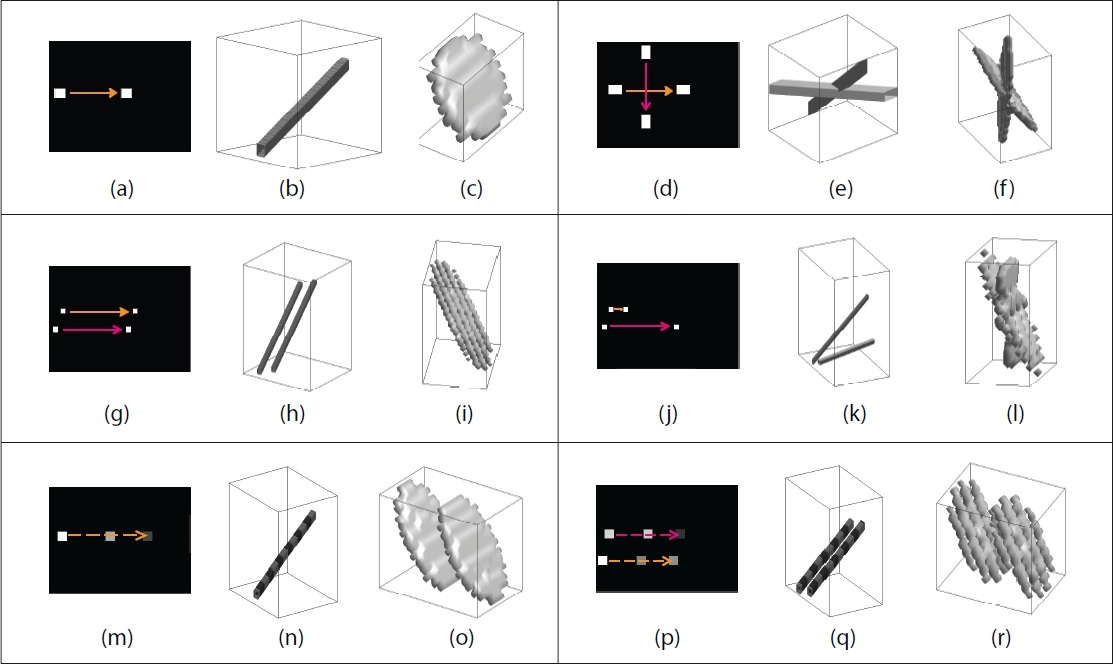
and a frequency spectrum of non-zero values on a plane (c). Similarly, motion in different orientations (d)
results in the volume in (e) and a frequency spectrum (f) with two planes. Uni-directional motion results in
a single plane in frequency spectum (g-i). Motion with different velocities (j) corresponds to two planes in
the frequency spectum (l). A translating object with a sinusoidal intensity over time (m-n) resulted in two
identical planes in the frequency spectrum with a separation based on the frequency of the object (o). For
multiple objects introducing more gradients (p,g), the planes are still present but they appear partially (i,r).
Since the motion can occur in different directions and frequencies, in our work we use 3-D Gabor filters of different orientations and center frequencies to effectively capture the motion information in a video clip. By filtering the frequency spectrum with a certain oriented filter and taking the inverse Fourier transform, the motion and scene components which are normal to the orientation of the filter are pronounced, as illustrated in the example in Figure 3.

spectrum for the sample clips (a,g), the components with different motion (b,c,h,i), the vertical scene
components (d,j), the horizontal scene components (e,k), and the diagonal scene components (f,l) are
highlighted. The red and cyan arrows show the direction of motion in the two videos.
Generating Descriptor
A flowchart describing the implementation of our method is depicted in Figure 4. Our goal is to represent each video sequence by a single global descriptor and perform the classification. For the current implementation, we extract K uniformly sampled clips of a fixed length from each given video.
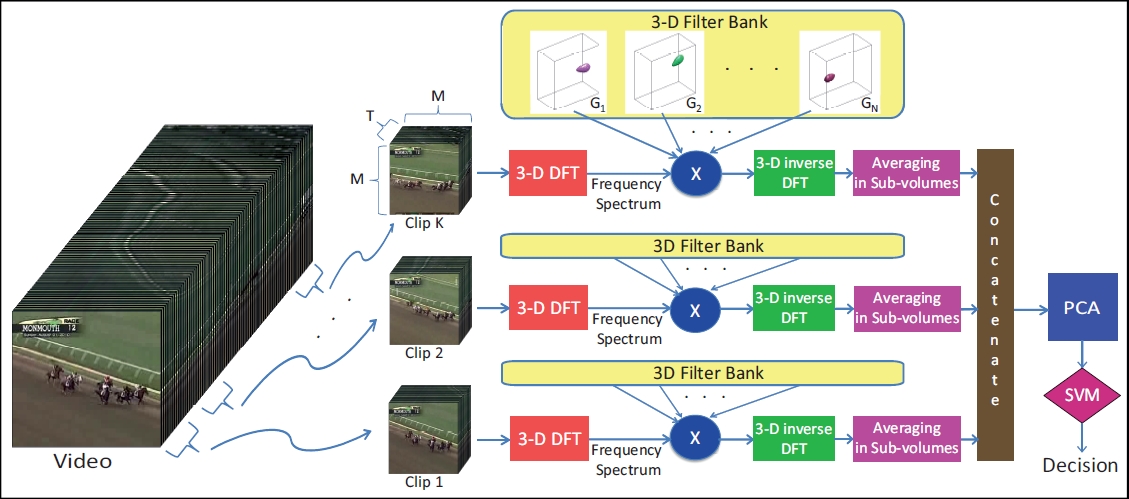
As the next step, we compute the 3-D DFT, and obtain the frequency spectrum of each clip as given by,
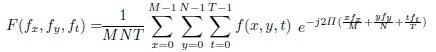
In order to capture the components at various intervals of the frequency spectrum of a clip, we apply a bank of narrow band 3-D Gabor filters with different orientations and scales. The transfer function of each 3-D filter, tuned to a spatial frequency fr0 along the direction specified by the polar and the azimuthal orientation angles θ0 and ϕ0 in a spherical coordinate system, can be expressed by,
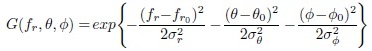
where
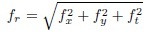 ,
, 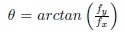 and
and 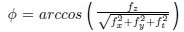 , and the parameters
σr , σθ and σϕ
are the radial and angular bandwidths, respectively, defining the
elongation of the filter in the spatio-temporal frequency domain. 3-D
plots of these filters are shown in Figure 5.
, and the parameters
σr , σθ and σϕ
are the radial and angular bandwidths, respectively, defining the
elongation of the filter in the spatio-temporal frequency domain. 3-D
plots of these filters are shown in Figure 5.
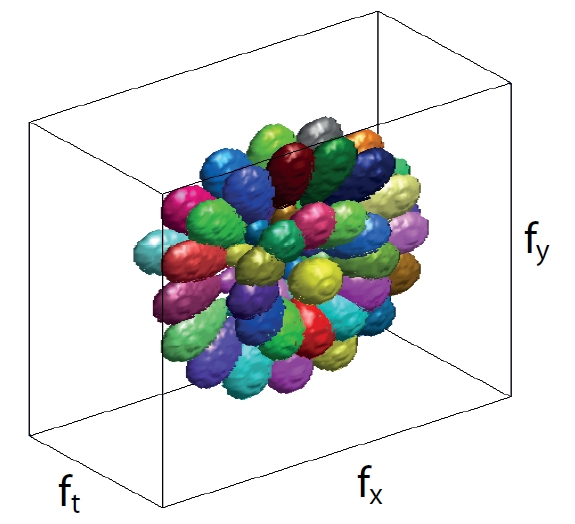
Applying each generated 3-D filter on the frequency spectrum of the clip, we compute the output,
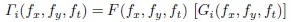
where Γi (fx, fy, ft) is the output when the ith filter is applied. Then we take the inverse 3-D DFT,
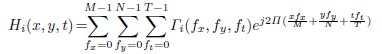 .
.
By quantizing the output volume in fixed sub-volumes and taking the sum of each sub-volume and performing the same computation for each filter in our filter bank, we obtain a long feature vector which represents a single clip. This feature vector has the advantage of preserving the spatial information as the response of each filter on each sub-volume contributes to an element in the concatenated feature vector. The last step is to apply PCA, a popular method for dimensionality reduction, in order to generate our global video descriptor.
Experimental Results
For performance evaluation, we used publicly available datasets: KTH Dataset, UCF50 Dataset, and HMDB51 Dataset. UCF50 and HMDB51 are the two most challenging datasets with the largest number of classes, which are collections of thousands of low quality web videos with camera motion, different viewing directions, large interclass variations, cluttered backgrounds, occlusions, and varying illumination conditions. For all experiments, we picked three key clips of 64 frames from each video and downsampled the frames of clips to a fixed size (128x128) for computational efficiency. Next, we computed the 3-D DFT to compute the frequency spectrum of the clips of each video and then applied the generated filter bank, which consisted of 68 3-D Gabor filters, which corresponded to 2 scales and 37 and 31 orientations for the first and second scales, respectively, in the spatiotemporal frequency domain. After the application of the filters, we computed the average response of filters on 512 uniformly spaced 16x16x8 subvolumes, in order to quantize and generate the global feature vector for the clip. The length of the feature vector in our experiments was 104,448, as there are 68 filters, 512 sub-volumes and 3 key clips. We reduced the dimensionality of the feature vectors to 2,000 using PCA. More details are provided in the related paper.
For classification, we trained a multi-class Support Vector Machine (SVM) using the linear kernel for our descriptor and histogram intersection kernel for STIP. We performed cross validation by leaving one group out for testing and training the classifier on the rest of the dataset and performing the same experiment for all groups on UCF50. For HMDB51 we performed cross validation on the three splits of the dataset. We did not include any clips of a video in the test set if any other clip of the same video is used in the training set.
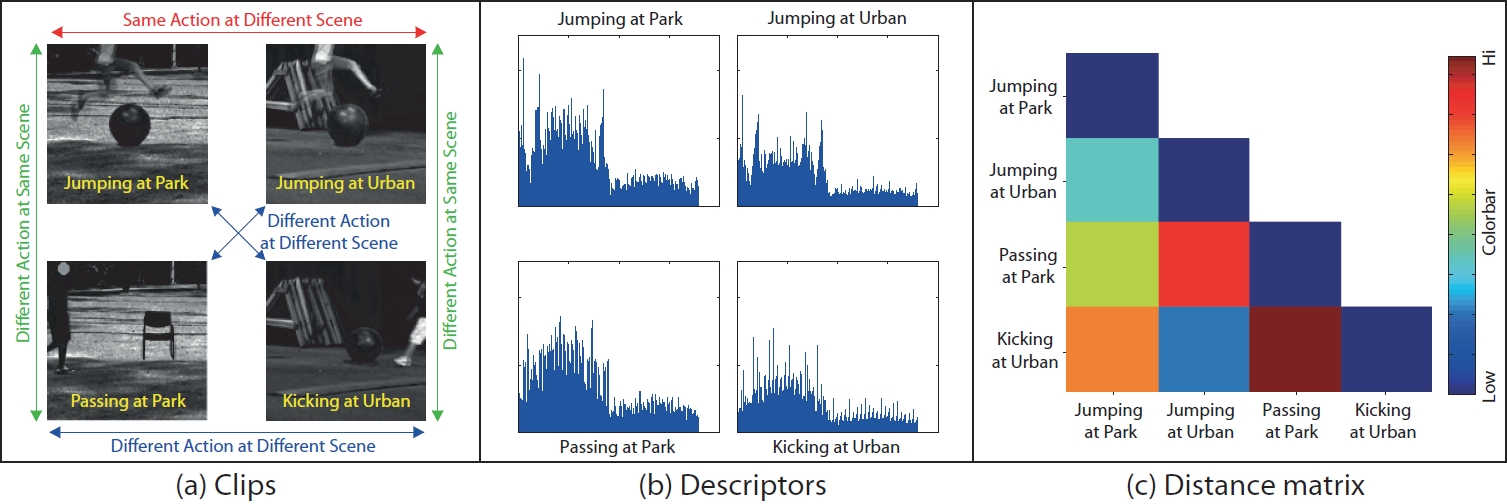
The discriminative power of our descriptor can be seen clearly in the example in Figure 6. This basic experiment was done using 4 sequences from a public dataset. For each of the 4 sequences, we computed the descriptors. Each entry in the matrix in Figure 6.c is the normalized Euclidean distance between the computed descriptors of the 4 sequences. As seen in the matrix, the descriptor distances between the jumping actions in two different scenes is comparably lower than the other distances, which shows that our descriptor can generalize over intra-class variations. The distances are high when different actions are performed in different scenes, such as the ones labeled by blue arrows in Figure 6.a.
To illustrate the advantage of the 3-D global descriptor, we compared our descriptor to the popular descriptors: GIST (on UCF50 dataset), and STIP (on KTH, UCF50 and HMDB51 datasets) which involve the computation of histograms of oriented gradients (HOG) and histograms of optical flow (HOF). For comparison, we also listed the performance of a low level descriptor based on color and gray values (on UCF50 and HMDB51 datasets), and the biologically motivated C2 features (on KTH and HMDB51 datasets). Fig. 8 shows the comparison of performance over three datasets. The conclusion tables are provided in the paper.
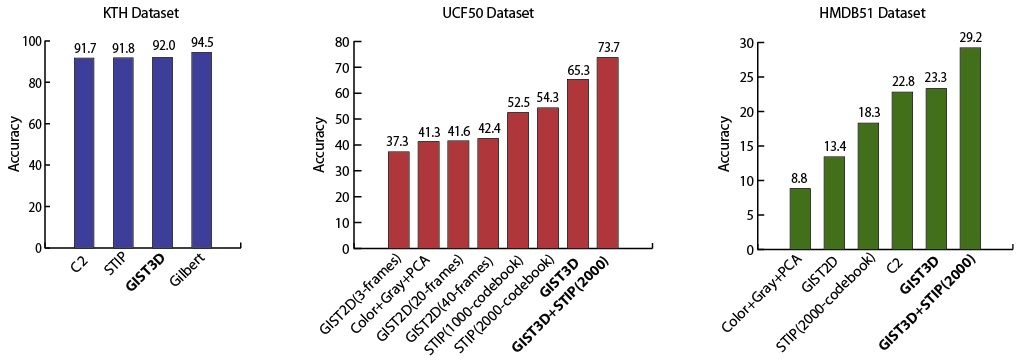
Figure 7. Average classification accuracies over KTH, UCF50 and HMDB51 datasets.
KTH Dataset:
The KTH dataset includes videos captured in a controlled setting of 6 action classes with 25 subjects for each class. Our descriptor has a classification accuracy of 92.0%, which is comparable to the state-of-the-art. This experiment shows that our descriptor is able to discriminate between the actions with different motions appearing in similar scenes.UCF50 Dataset:
This dataset includes unconstrained web videos of 50 action classes with more than 100 videos for each class. Our descriptor has an accuracy of 65.3% over 50 action classes, which outperforms GIST and STIP. Using the combination of STIP and GIST3D by late fusion resulted in a classification accuracy of 73.7%, which is another 8% improvement in the performance.For comparison of our descriptor to STIP, we also analyzed the average similarities of descriptors among action classes of UCF50. We computed the Euclidean similarity for our descriptors and histogram intersection as the similarity measure for STIP. Our descriptor has higher intra-class similarity and lower inter-class similarity than STIP as shown in Figure 8. This clearly explains why our global descriptor (GIST3D) performs superior than STIP.
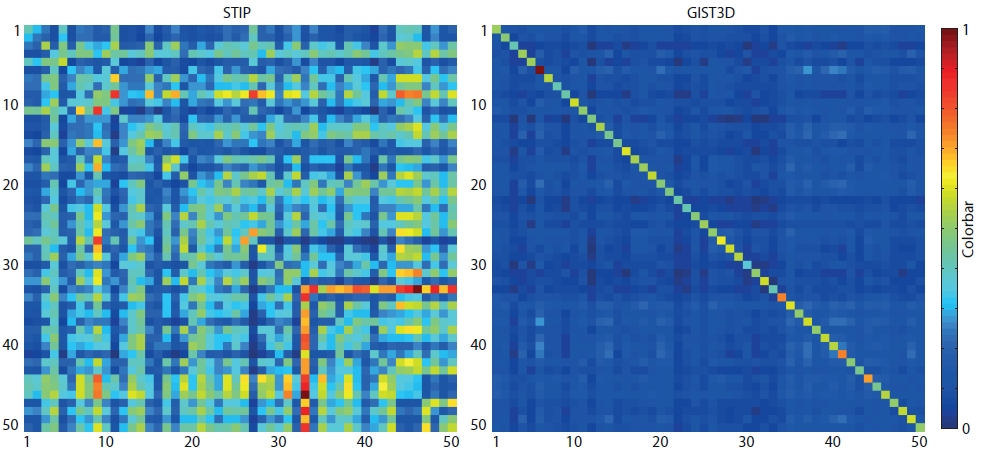
Figure 8. Descriptor similarity matrices for STIP (a) and GIST3D (b) computed among 50 action classes of UCF50 dataset.
HMDB51 Dataset:
The HMDB51 dataset includes videos of 51 action classes with more than 101 videos for each class. Our descriptor has a classification accuracy of 23.3% over 51 action classes, which outperforms STIP by 5%. The late fusion classifier of these two descriptors resulted in a 6% improvement in the performance over using just our descriptor GIST3D.The actions in the video sequences of HMDB51 are not isolated; multiple actions may be present in a single video sequence despite a given single class label for the sequence. There is also large intraclass scene variation. Therefore, classifying actions on this dataset is more challenging and the performances of the mentioned methods are lower.
Conclusion:
In this work, we presented a global scene and motion descriptor to classify realistic videos of different actions. Without interest point detection, background subtraction and tracking, we represented each video with a single feature vector and obtained promising classification accuracies using a linear SVM. Preserving also the useful spatial information, our descriptor had a better performance than the state-of-the-art local descriptor, STIP, utilizing a bag-of-features representation which discards the spatial distribution of the local descriptors.Related Publication
Berkan Solmaz, Shayan Modiri A., and Mubarak Shah, Classifying Web Videos using a Global Video Descriptor, Machine Vision and Applications (MVA), 2012.
(pdf file)
(bibtex)