Modeling
Traffic Patterns for Vision based Surveillance Applications
Related Publication:
Introduction
With the proliferation of wide area video sensor networks,
video surveillance, especially in public areas, is gaining importance at an unprecedented
rate. From closed-circuit security systems that can monitor individuals at
airports, subways, concerts, and densely populated urban areas in general, to
video sensor networks blanketing important location within a
city, automated vision based surveillance is the tool required for
processing these continuous streams of data. Over the years, a major effort in
the vision community has been concentrated on developing fully automated
surveillance, monitoring and security systems. Such systems have the advantage
of providing 24 hour active warning capabilities and are especially useful in
the areas of law enforcement, national defense, border control, and airport
security. The current systems are efficient and robust in their handling of
common issues, such as illumination changes, shadows, weather conditions, and
noise in the imaging process. However, most of these systems have short or no
memory in terms of observables in the scene. Due to this memory-less behavior,
these systems lack the capability of learning the environment parameters and
intelligent reasoning based on these parameters. Such learning and reasoning is
an important characteristic of all cognitive systems that increases the
adaptability and thus the practicality of such systems. A number of studies
have provided strong psychological evidence of the importance of context for
scene understanding in humans, such as, handling long term occlusions,
detection of anomalous behavior, and even improving the existing low-level
vision tasks of object detection and tracking.
We argue that over the period of its operation, an
intelligent tracking system should be able to learn the scene from its
observables and be able to improve its performance based on this model. The
high level knowledge necessary to make such inferences derives from domain
knowledge, past experiences, as well as scene geometry, learned traffic and
target behavior patterns in the area, etc.
This argument forms the basis of this project, where we model and learn
the scene activity, observed by a static camera. The motion patterns of the
objects in the scene are modeled as a multivariate non-parametric probability
density function of spatio-temporal variables. Kernel
density estimation is used to learn this model in a completely unsupervised
fashion, by observing the trajectories of objects over extended periods of
time.
Approach
The scene model is learned by observing object
trajectories over a long period of time. These trajectories may have errors due
to clutter and may also be broken due to short and long term occlusions.
However, by observing enough tracks, one can acquire a fairly good
understanding of the scene, and infer such scene properties and salient
features as usually adapted paths, frequently visited areas, occlusion areas,
entry / exit points, etc. It is assumed that the tracks of moving objects for
training are available. The KNIGHT object detection and tracking system,
developed at the UCF Vision Lab, is used for obtaining the tracks. These tracks
are then used in a training phase to discover the correlation in the
observations by learning the motion pattern model in the form of a multivariate
pdf of spatio-temporal
parameters (i.e. the joint probability density of pairs of observations of an
object occurring within certain time intervals). Kernel density estimation is
used to learn the form of this probability density function.
After the learning phase, a unified Markov chain Monte
Carlo (MCMC) sampling based framework is used to generate the most likely paths
in the scene, to decide whether a given path is an anomaly to the learned
model, and to estimate the probability density of the next state of a random
walk based on its previous states. These predictions based on the model are
then used to improve the detection of foreground objects as well as to
persistently track objects through short-term and long-term occlusions.
Novelty
The work performed in this project is original in the
following ways:
·
A novel motion model is proposed that not only
learns the scene semantics but also the behavior of traffic through arbitrary
paths. This learning is not limited like other approaches that work best with
well defined paths like roads and walkways.
·
The learning is accomplished using a joint five
dimensional model unlike pixel-wise models and mixture or chain models. The
proposed model represents the joint probability of a transition from any point
in the image to any other point, and the time taken to complete that
transition.
·
The temporal dimension of traffic patterns is
explicitly modeled, and is included in the feature vector, thus enabling us to
distinguish patterns of activity that correspond to the same trajectory cluster
but have high deviation in the temporal dimension. This is a more generalized
method as compared to modeling pixel-wise velocities.
·
Instead of fitting parametric models to the data,
we propose the idea of learning tracks information using Kernel Density
Estimation. It allows for a richer model and the density retained at each point
in the feature space accurately reflects the training data.
·
Rather than exhaustively searching for predictions
in the feature space based on their probabilities, we propose to use stochastic
methods to sample from the learned distribution and use it as prediction with a
computed probability. Sampling is thus used as the process propagation function
in our state estimation framework.
·
Unlike most of the previous work reported in this
section, which is targeted towards one or two similar applications, we apply
the proposed probabilistic framework to solve a variety of problems that are
commonly encountered in surveillance and scene analysis.
Learning
the Transition Distribution using KDE
The object transition model has a single five dimensional
feature z = (X, Y, Δt), where X is the two
dimensional initial location of the object in image coordinates, Y is the two
dimensional final location in image coordinates, and Δt
is the time taken to complete the transition in milliseconds. The KNIGHT system
outputs object trajectories as a series of observations, where each observation
is associated with the location of object centroid
and the time at which the object was observed. After obtaining these trajectories,
each distinct pair of observations, belonging to the same object, is added to
the kernel density estimate as the five dimensional data point z, where the centroid location of object in the first observation
becomes X, location in the second observation of the pair becomes Y, and Δt is computed as the time difference between the
instants of the two observations. Δt
is assumed to be less than or equal to 5000 milliseconds to keep an upper bound
on the number of data points per trajectory. Observations,
even of the same object, occurring more than 5 seconds apart are assumed to be
uncorrelated. Kernel density estimation is used as the learning
methodology.


Fig: Two scenes used for testing. Tracks observed during
training are shown in blue.




![]()
Fig: Maps representing marginal probability of an object, (a)
reaching each point in the image, (b) starting from each point in the image, in
any
duration of time. (c) and (d) show similar maps for a
different scene.
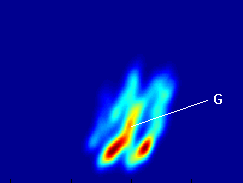
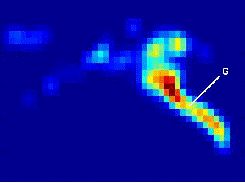
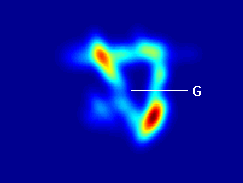
Fig: Regions of maps showing probability of reaching any
point in the map starting from the point G.
Applications
of Proposed Model
After learning, a joint MCMC based framework is used to
sample from the model and generate predictions for future locations of objects
given the current state. These predictions are then used to attempt the
solution of diverse problems that are commonly encountered in surveillance
scenarios.
- Generating
Likely Tracks
Generation of likely paths is an important aspect of
modeling traffic patterns. Given the current location of an object,
such a simulated path amounts to a prediction of future behavior of the object.
We seek to sample from the learned model of transition patterns to generate behavior
predictions. We expect that only a few number of paths
should adequately reflect observations of trajectories through walkways and
roads, etc. Starting at random initial states in the image, sampling from the
distribution gives possible paths that are usually followed by the traffic.
The figure below shows some of these random walks. It
should be noted that no observations from the tracking algorithm have been used
in this experiment. The likely paths generated are purely simulated based on
the learned distribution.

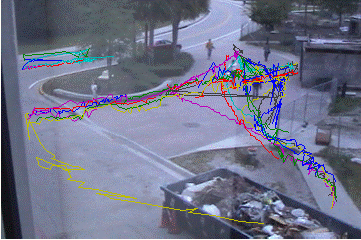

Fig: Examples of simulated likely paths generated by the
proposed algorithm using Metropolis-Hastings sampling. Tracks are initialized
by manually selecting random points.
- Improvement
of Foreground Detection
The intensity difference of objects from the background has
been a widely used criterion for object detection, but it can be noted that
temporal persistence is also an intrinsic property of the foreground objects,
i.e. unless an object exits from the scene or becomes occluded, it has to either
stay at the same place or move to a location within the spatial vicinity of the
current observation. Since our proposed transition model incorporates the
probabilities of movement of objects from one location to another, it can be
used to improve the foreground models. We now present the formulation for this
application. It should be noted however that this method alone cannot be used to
model the foreground. Instead it needs to be used in conjunction with an
appearance based model like mixture of Gaussians. Essentially, the transition
probabilities of objects from one point to another, are
used as evidence of temporal persistence of foreground, for each pixel in the
foreground blob in the previous time instance.








Fig: Foreground Modeling Results: Columns (a) and (b) show
results of object detection. The images in top row are without and bottom row
are with
using the proposed model. Green and red bounding boxes show true and false
detections respectively. (c) and (d) show results of
blob tracking. Red
tracks are original broken tracks and black ones are after improved foreground
modeling.
- Anomaly
Detection
If tracking data used to model the state transition
distribution spans sufficiently large periods of time, it is obvious that a
sampling algorithm will not be able to sample a track that is anomalous
considering the usual patterns of activity and motion in that scene. This observation
forms the basis of our anomaly detection algorithm. The anomaly detection
algorithm generates its own predictions for future states using MCMC sampling,
without using the current observation of the tracker. It then compares the
actual measurements of objects with the predicted tracks and computes a
difference measure between them.
This approach is sufficient to find a sequence of
transitions significantly different than the predictions from the state
transition distribution, and can easily identify an anomalous event in terms of
motion patterns. Using this formulation trajectories that are spatially incoherent, or temporally inconsistent with normal behavior can
be identified, e.g., presence of objects in unusual areas or significant speed
variation respectively.











(a)
(b)
(c)
(d)
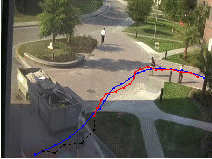
Fig: Results of Anomaly detection: (a) Spatially anomalous,
(b) and (c) Temporally anomalous, and (d) Suspicious behavior due to
presence over large distance or extended period. Blue track represents the
actual (observed) track. Red and black tracks correspond to
typical and atypical (anomalous) predicted paths respectively.
- Persistent
Tracking through Occlusions
Persistent tracking requires modeling of spatio-temporal and appearance properties of the targets.
Traditionally, parametric motion models such as, constant velocity or constant
acceleration, are used to enforce spatio-temporal
constraints. These models usually fail when the paths adapted by objects are
arbitrary. The proposed model of learning traffic parameters is able to handle
these shortcomings when occlusions are not permanently present in the scene and
the patterns of motion through these occlusions have previously been learned,
e.g., person to person occlusions, large objects like vehicles that hide smaller
moving objects from view. We use the proposed distribution to describe a
solution to these problems.
Essentially, once the tracking algorithms realizes that
the tracking of an object has been lost, it starts generating its own predicted
locations for that object and continues until the object becomes visible again.
This way when the object becomes visible after undergoing an occlusion, the
current prediction is much closer to the actual current position, as compared
to the last observed position and hence, the solution to the correspondence
problem becomes simpler and more robust.






(a)
(b)
(c)
Fig: For each row, (a) shows the observed tracks in blue
and red that have been labelled wrong, and
(b) and (c) show the stitched part of
tracks in black, and actual tracks in red and blue respectively.


Fig: Example of persistent tracking for multiple
simultaneous objects with overlapping
or intersecting tracks undergoing occlusion. (Left) Actual original tracks
(ground truth) (Right) Broken tracks due to simulated occlusion shown as black
region.

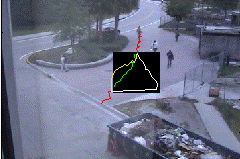
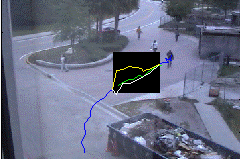

Fig: Results for scenario shown in previous figure. Green track
is the ground truth. Tracking through occlusion using Kalman
filter is shown in white and
yellow tracks are generated using the proposed approach. Notice that both methods
can recover well once the measurement is available again, but
during occlusion the proposed method stays closer to ground truth.