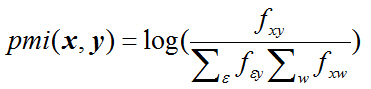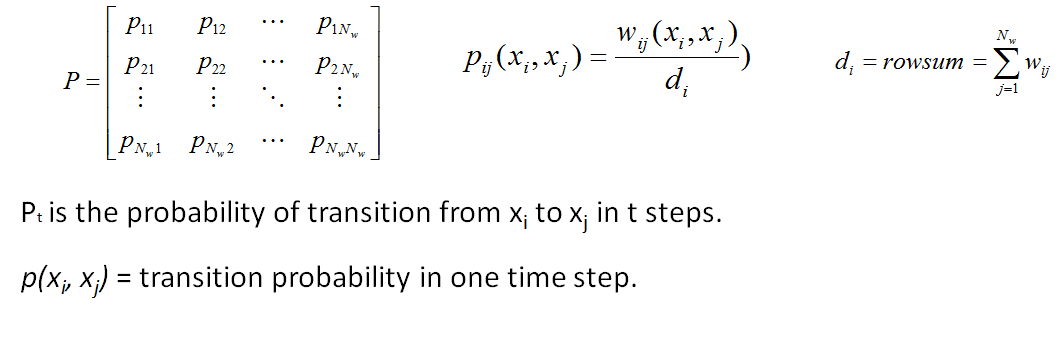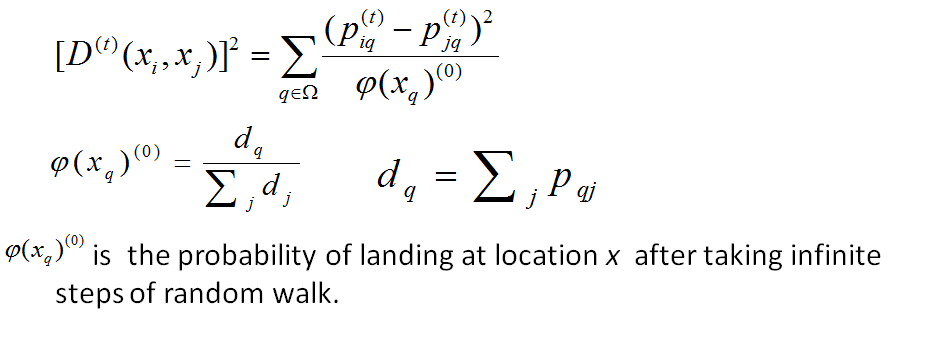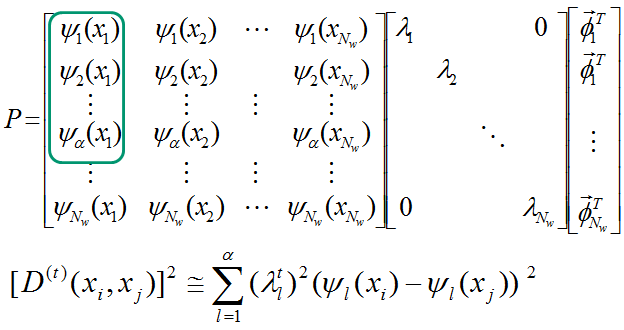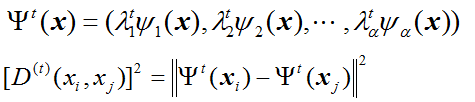|
Learning Semantic Visual Vocabularies Using
Diffusion Distance Related Publication: Jingen Liu, Yang Yang and Mubarak Shah, Learning Semantic Visual Vocabularies Using Diffusion Distance, IEEE International Conference on Computer Visiona and Pattern Recognition (CVPR), 2009. |
|||||||
|
|||||||
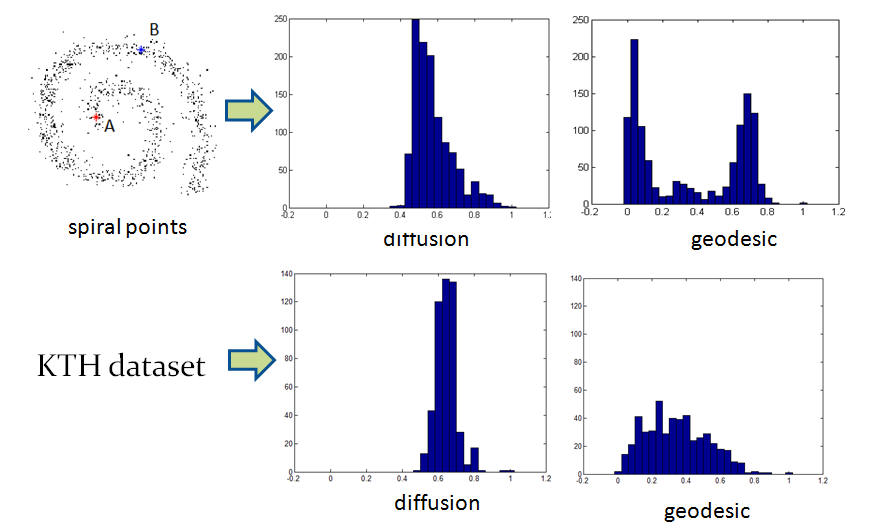
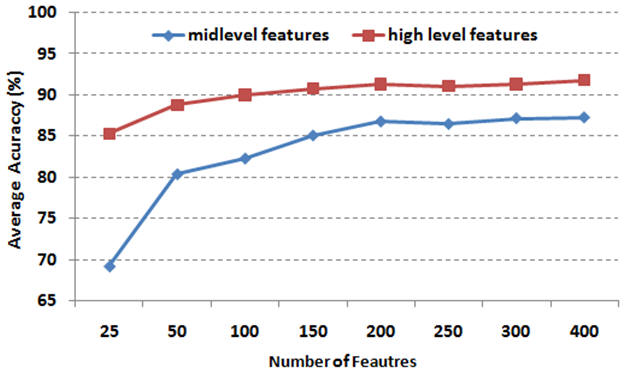
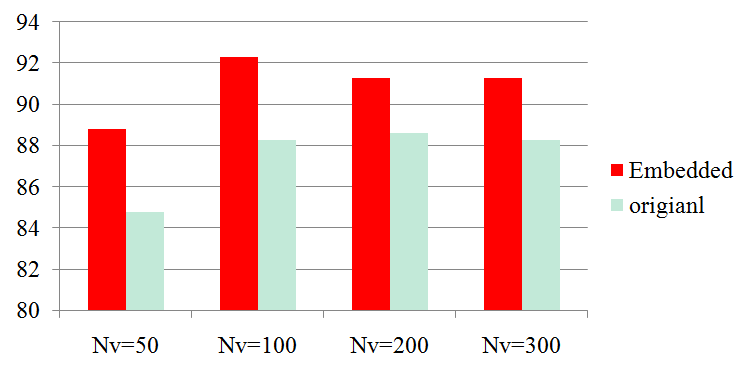
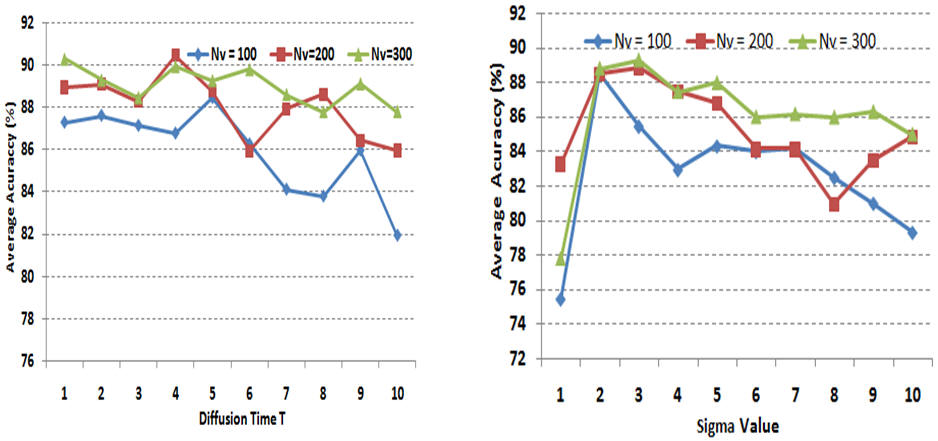
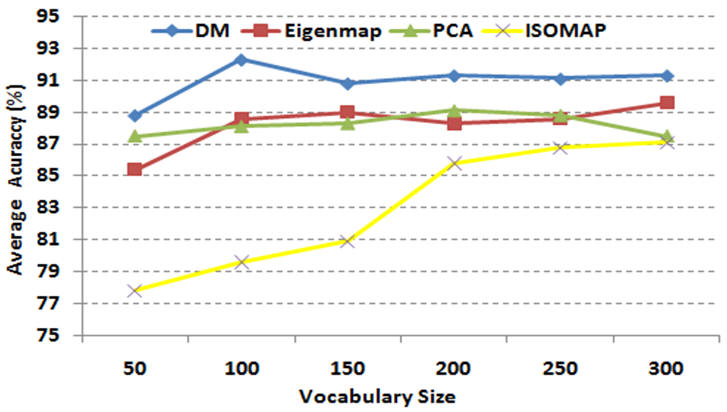
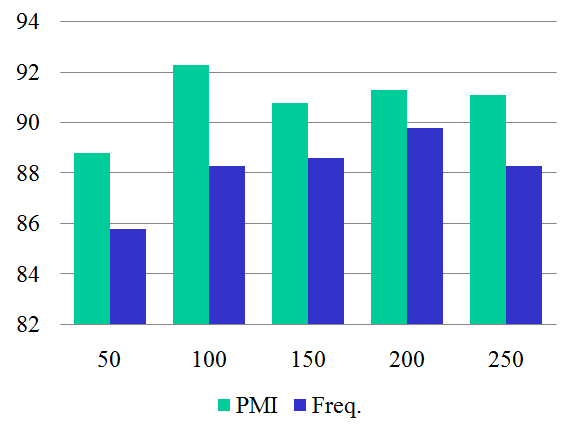
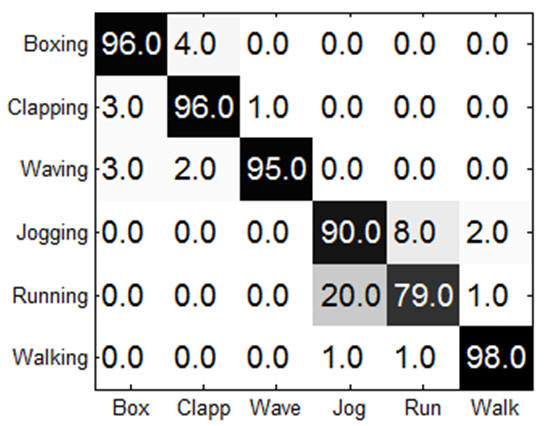
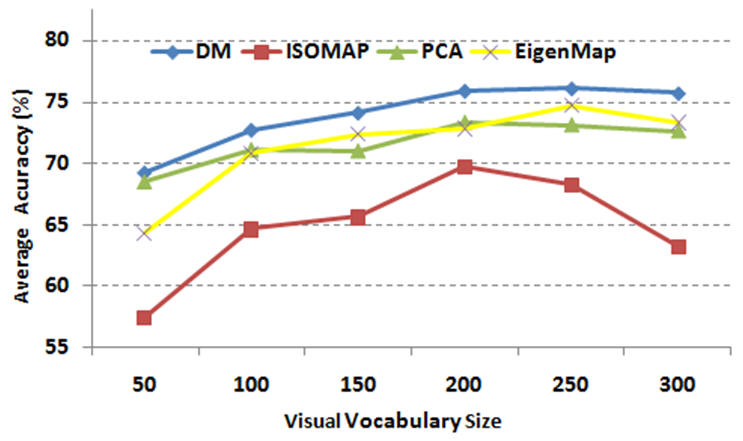
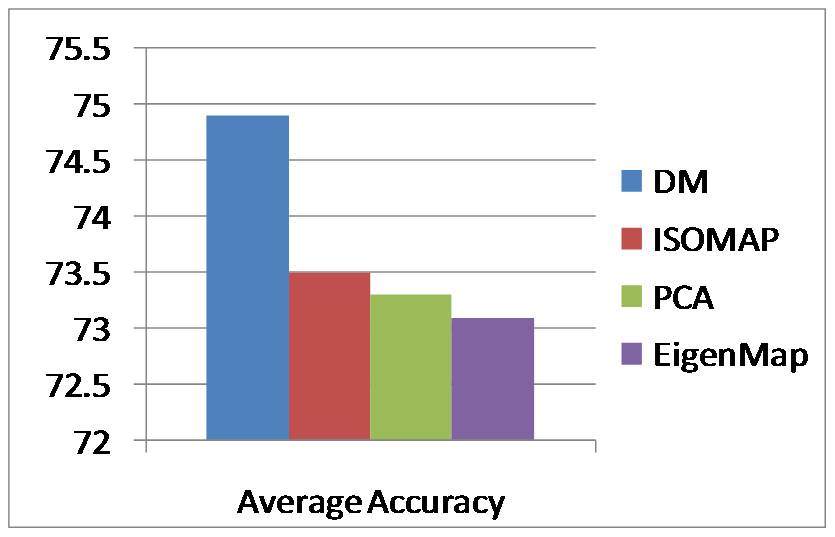
IntroductionBag of features (BOF) is receiving increasing attention due to its simplicity and surprisingly good performance on object, scene and action recognition problems. The underlying idea is that a variety of statistical cues are present in images and videos, such as color or edge patterns and local spatiotemporal patterns, which can be effectively used for recognition. However, there are some problems of BOF: Larger codebook size can achieve better performance, but it also results in sparse high-dimensional vectors; Visual words are not semantically meaningful. We propose a novel approach to further cluster visual words and generate a semantic vocabulary for visual recognition. We use diffusion maps to automatically learn a semantic visual vocabulary from abundant quantized midlevel features. Each midlevel feature is represented by the vector of pointwise mutual information (PMI). In this midlevel feature space, we believe the features produced by similar sources must lie on a certain manifold. To capture the intrinsic geometric relations between features, we measure their dissimilarity using diffusion distance. The underlying idea is to embed the midlevel features into a semantic lower-dimensional space. Although the conventional approach using k-means is good for vocabulary construction, its performance is sensitive to the size of the visual vocabulary. In addition, the learnt visual words are not semantically meaningful since the clustering criterion is based on appearance similarity only. Our proposed approach can effectively overcome these problems by capturing the semantic and geometric relations of the feature space using diffusion maps. Unlike some of the supervised vocabulary construction approaches, and the unsupervised methods such as pLSA and LDA, diffusion maps can capture the local intrinsic geometric relations between the midlevel feature points on the manifold. We have tested our approach on the KTH action dataset, our own YouTube action dataset and the fifteen scene dataset, and have obtained very promising results. |
|||||||
Flowchart
of Learning Semantic Visual Vocabulary
|
|||||||
1. Major steps
for constructing a semantic visual vocabulary using diffusion maps. |
|||||||
2. Raw feature extraction
fxy= cxy/Nt, cxyis the number of times feature y appears in image or video x.
|
|||||||
Diffusion Maps |
|||||||
|
Construct weighted graph
Markov Transition Matrix
Diffusion distance
Diffusion maps embedding
|
|||||||
Advantages Over Other Manifold Approaches |
|||||||
|
|||||||
|
|||||||
Downloads |