Introduction
In this project, we introduce the Action MACH filter, a template-based method for action recognition which is capable of capturing intra-class variability by synthesizing a single Action MACH filter for a given action class. We generalize the traditional MACH filter to video (3D spatiotemporal volume), and vector value data such as optical flow.
By analyzing the response of the filter in the frequency domain, we avoid the high computational cost commonly incurred in template-based approaches, thereby reducing detection to a matter of seconds. Vector-valued data is analyzed using the Clifford Fourier transform, which is generalization of the traditional scalar-valued Fourier transform.
Extending Traditional MACH Filters
Traditionally, MACH filters have been employed in object classification, palm print identification , and aided target recognition problems. Given a series of instances of a class, a MACH filter combines the training images into a single composite template by optimizing four performance metrics: the Average Correlation Height (ACH), the Average Correlation Energy (ACE), the Average Similarity Measure (ASM), and the Output Noise Variance (ONV). This procedure results in a two dimensional template that may express the general shape or appearance of an object. Templates are then correlated with testing sequences in the frequency domain via a FFT transform, resulting in a surface in which the highest peak corresponds to the most likely location of the object in the frame.
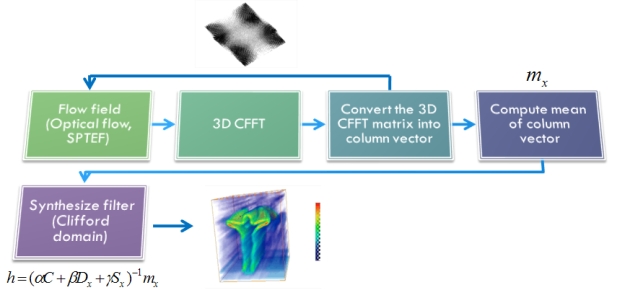
The notion of a traditional MACH filter could be generalized to encompass human actions in a number of ways. A fairly straightforward approach would be to recognize an action class by a succession of two dimensional MACH filters at each frame. However, in order to fully leverage the information contained in a video sequence, the approach we propose in this work consists of generalizing the MACH filter by synthesizing a template estimated from the spatio-temporal volumes of action sequences. Such filters could be synthesized using raw pixel values, edges, temporal derivative, or optical-flow in the spatiotemporal volume. When each pixel in this volume contains multiple values (e.g. optical flow), it is not possible to synthesize a MACH filter using traditional Fourier transform. Solutions to this problem could include employing motion magnitude or direction alone (scalar values), instead of complete optical flow vector. In order to deal with this problem, we propose to employ the Clifford transform, which is a generalization of the standard Fourier transform for vector valued functions.
The Clifford Fourier Transform
Clifford
algebra extends the Euclidean space to a real algebra. For a
three-dimensional Euclidean vector space we obtain an eight-dimensional
space having the bases of a real vector space. Elements belonging to
this algebra are referred to as multivectors, the structure of the
algebra is given by . Based on this algebra, a set of of basic
operators can be defined to generalize Euclidian space to encompass
vector fields. These include not only operations such as Clifford
multiplication and integrals but also composite operations such as
Clifford Convolution and the Clifford Fourier Transform.

A multivector field in Clifford space corresponding to a thee-dimensional Euclidian vector field can be regarded as four complex signals which are independently transformed by a standard complex Fourier transformation. Therefore, the Clifford Fourier transform can be defined as a linear combination of several classic Fourier transforms. As a result, all of the well known theorems that apply to the traditional Fourier transform hold for the CFT. We exploit this property by applying FFT-like algorithms to accelerate the computation of the CFT, thereby reducing computation to a matter of seconds.
Since scalars and vectors are part of multivectors, both scalar and vector-valued fields can be regarded as multivector fields. Therefore, the described Clifford embedding becomes a unifying framework for scalar, vector, and multivector-values filters.
Experiments and Results
We performed an extensive set of experiments to evaluate the performance of the proposed method on a series of publicly available datasets and on a collection of actions found in feature films and broadcast television.
Feature Films

Feature Films We have compiled a dataset of actions performed in a range of film genres consisting of classic old movies such as “A Philadelphia Story”, “The Three Stooges” and “Gone With the Wind”, comedies such as “Meet the Parents”, a sci-fi movie titled “Star Wars”, a fantasy movie “The Lord of the Rings: The Return of the King” and romantic films such as “Connie and Carla”. This dataset provided a representative pool of natural samples of action classes such as “Kissing” and “Hitting/slapping”. We extracted 92 samples of the “Kissing” and 112 samples of “Hitting/Slapping”. The extracted samples appeared in a wide range of scenes, view points and performed by different actors. Instances of action classes were annotated by manually selecting the set of frames corresponding to the start and end of the action along with the spatial extent of the action instance.
Testing for this dataset proceeded in a leave-one-out framework. Each action class consisting of n video sequences was partitioned such that n - 1 sequences were used for training, leaving the remaining video sequence as a testing set. This process is repeated for each of the n sequences. Given the significant intra-class variability present in the movie scenes, the recognition task is challenging. In our experiments using SPREF, we achieved a mean accuracy of 66.4%for the “Kissing” action, and a mean accuracy of 67.2% for the “Hitting/Slapping”action.
UCF Sports Action Dataset

We have collected a set of actions from various sports which are typically featured on broadcast television channels such as the BBC and ESPN. Video sequences were obtained from a wide range of stock footage websites including BBC Motion gallery, and GettyImages.
Actions in this dataset include:
- Diving (16 videos)
- Golf swinging (25 videos)
- Kicking (25 videos)
- Lifting (15 videos)
- Horseback riding (14 videos)
- Running (15 videos)
- Skating (15 videos)
- Swinging (35 videos)
- Walking (22 videos)
- Pole vaulting (15 videos)
This new dataset contains close to 200 video sequences at a resolution of 720x480. The collection represents a natural pool of actions featured in a wide range of scenes and viewpoints. By releasing the dataset we hope to encourage further research into this class of action recognition in unconstrained environments.
The overall mean accuracy for this dataset using our method was 69.2%. Given the difficulty of the dataset, these results are rather encouraging.
Conclusion
We have introduced the Action MACH filter, a method for recognizing human actions which addresses a number of drawbacks of existing template-based action recognition approaches. Specifically, we address the ability to effectively generate a single action template which captures the general intra-class variability of an action using a collection of examples. Additionally, we have generalized the traditional MACH filter to operate on spatiotemporal volumes as well as vector valued data by embedding the spectral domain into a domain of Clifford algebras.
The results from our extensive set of experiments indicate that the proposed method is effective in discriminating a wide range of actions, these include both whole-body motions (such as jumping jacks or waiving), to subtle localized motions (such as smiling or raising eyebrows). Additionally, by analyzing the response of the Action MACH filter in the frequency domain, we avoid the high computational cost which is commonly incurred in template-based approaches.
Resources:
Source code (Matlab/C++)