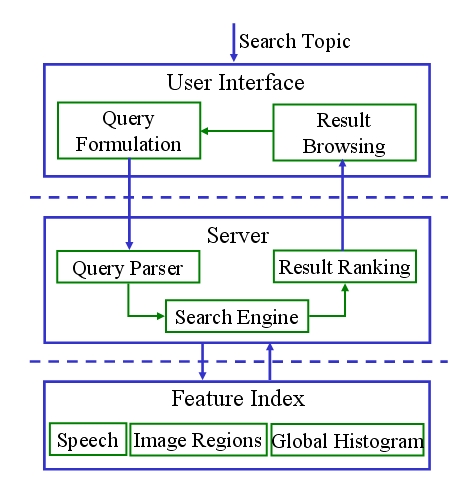
PEGASUS is a content-based video retrieval system developed at the UCF Computer Vision Lab. It is designed for retrieving relevant videos from broadcast news programs given the target topics. It utilizes the content of the videos, such as speech transcript and visual content, for fast indexing and search. It consists of three components: user interface, server and feature index system. The query formulation and result browsing are performed through the user interface. The server component parses the input query, performs the search and ranks the returned results. The index system contains the indexing results of the video features. Two types of relevance feedback mechanisms, automatic keyword generation and region-based visual refinement, have been developed and embedded in the system to improve the searching performance. The system diagram is shown in Figure 1.
|
Figure 1. System diagram of PEGASUS with three major components and their functions. |
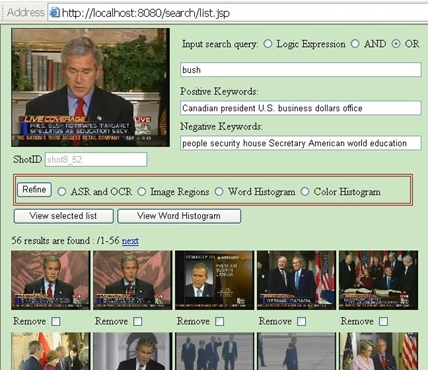
One important feature of the PEGASUS system is to automatically generate the relevant keywords to refine the search query. For different video sets, the initial query formulated based on prior human knowledge often is not strongly related to the topic. By analyzing the user selected relevant video shots, a set of keywords, which are more correlated to the topic, are extracted. The extracted keywords are ranked by their frequencies in the relevant shots to represent their relevance to the search topic. They are used to assist the user to reformulate the search query, which is more relevant and meaningful for the target dataset. The snap shot of the keyword generation is shown in Figure 2.
|
Figure 2. Interface of the keywords generation. The selected relevant shots are shown in the panel. Both the positive and negative keywords are generated. |
Different news networks may broadcast the same news story, but with different narration. In this situation, the visual appearance of the video key-frames becomes an useful cue for finding the similar videos. The second relevance feedback mechanism of the PEGASUS system is based on the analysis of the key-frame regions. After the user decides the relevant shots in the previous round, each region in the selected key-frames is considered as a new query for the new round of search. The returned results are ranked based on the Earth Mover's Distance between the returned key-frames and the query key-frames. One snap shot of the visual refinement is shown in Figure 3.

|
Figure 3. Results of the visual refinement. The query images are shown in the left panel, each of which is followed by its similar shots. |
To demonstrate the effectiveness, we have tested on ten topics selected from TRECVID dataset. The refinement using the automatically generated keywords increases the relevant set by ~80%, which the visual refinement increases the relevant results by ~44%.Some search topic results are shown in figure 4.
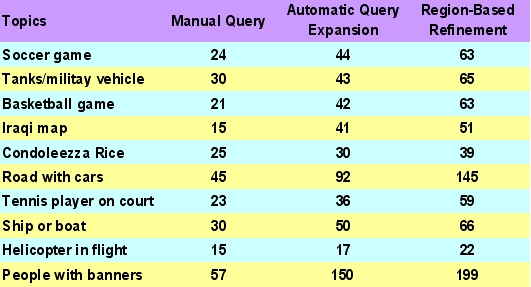
| Figure 4. Evaluation results of ten search topics. The numbers of relevant shots are shown separately for: (1) using the manual query only. (2) applying the automatic query expansion using keyword histogram and (3) applying the region-based refinement |