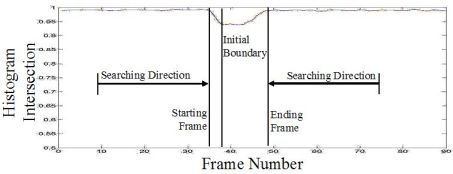
A video shot is defined as a sequence of video frames with continuous background settings. It is the smallest video unit containing temporal semantics, such as action, dialog, etc. In this work, I have proposed a multi-level framework for detecting the transition locations between video shots by analyzing the feature plots in different temporal scales of the input video sequence. The shot transitions are further classified into category of “abrupt” or “gradual” based on the accumulative changes around the neighborhoods of the transitions.
Scene Segmentation of Video Sequences
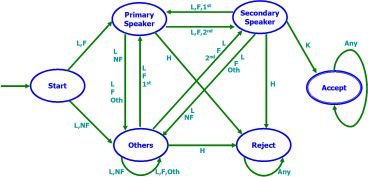
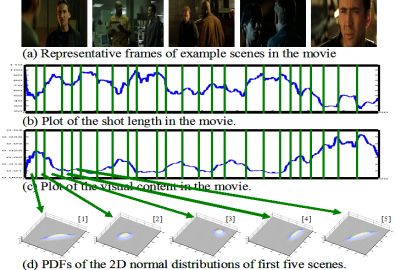
A scene is defined a group of video shots that are related to the same subject, e.g., chapters in movies, stories in news programs, etc. In this work, I have developed a general framework for temporal scene segmentation in various video domains. The developed framework is formulated in a statistical fashion and uses the Markov chain Monte Carlo (MCMC) technique to determine the boundaries between video scenes. In this approach, a set of arbitrary scene boundaries are initialized at random locations and are automatically updated using two types of updates: diffusion and jumps. The major advantage of the proposed framework is two-fold: 1) it is able to find the weak boundaries as well as the strong boundaries, i.e., it does not rely on the fixed threshold; 2) it can be applied to different video domains. The proposed scene segmentation framework has been applied on home videos and feature films, very promising results have been obtained for both domains.
Story Detection in News Videos
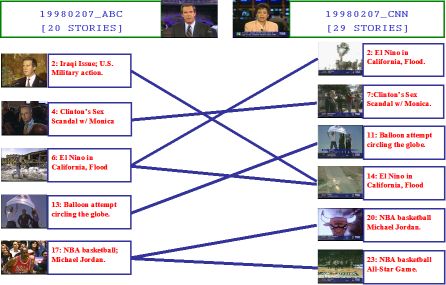
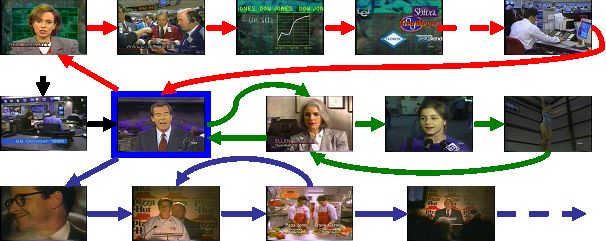
A particular interest exists in detecting stories in news videos. The results of the news story segmentation can be further applied in tasks, such as video summarization, indexing and retrieval. In this work, I have developed a new framework for segmenting the news programs into different story topics. The proposed method is constructed based on the Shot Connectivity Graph and utilizes both visual and textual contents of the video. With a series of anchor detection, weather and sporting news localization and story merging processes, the input news videos is finally segmented into stories, each of which consists coherent semantic contents. This work has achieved very high accuracy in the TRECVID evaluation competition 2004, and UCF vision team was invited to given an oral presentation in the forum.
Scene Structuring in Continuously Recorded Videos
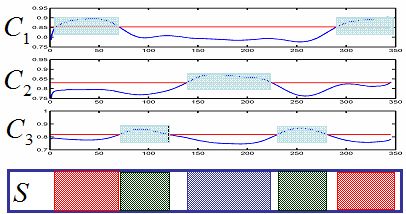
Instead of finding the abrupt scene boundaries, video scenes are represented by their corresponding representative feature values such as color statistics, and each portion of the video is indicated by a fuzzy number computed based on the membership functions with respect to the representative feature values. These representative feature values are obtained by applying spectral clustering technique. The scene segments are later determined by the preferred criteria. Different from the shot-based methods, the proposed method finds the scene boundaries not only based on the data (video shots), but also based on the user preference.