 Benjamin Mears
Benjamin Mears

Bootstrapping
A major challenge of the Trecvid dataset is the imbalance between positive and negative training examples. While there is an abundance of negative examples, for some features there are less than a 100 positive examples in the training data. In order to not bias the classifier, a balance between positive and negative training images must be maintained.
Some negative examples may be harder to classify than others and bootstrapping attempts to identify the hardest set of training data. The figure below illustrates the main idea of bootstapping.
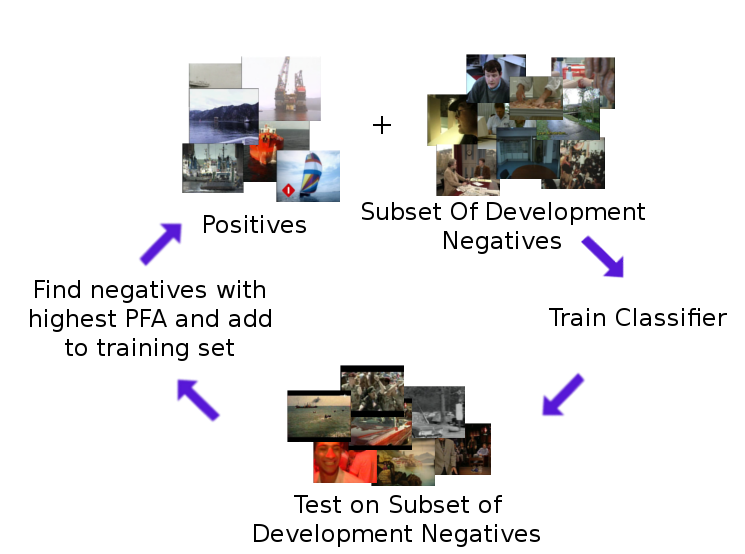
In each iteration, all the positive training examples along with an equal number of negative examples are used to create an SVM classifier. We then classify the rest of the negative development set and add to the training set the examples which the SVM classifier predicts to be positive with the highest certainty. We maintain a balanced training set by adding variations of positive examples created by applying various filters such as a Gaussian filter and histogram equalization.