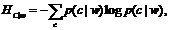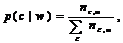|
Video Scene Understanding Using Multi-scale Analysis Related Publication: Yang Yang, Jingen Liu and Mubarak Shah, Video Scene Understanding Using Multi-scale Analysis, IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 2009. |
|
IntroductionScene understanding may involve, understanding the scene structure (e.g. pedestrian sidewalks, east-west roads, north-south roads, intersections, exits and eateries), scene status (e.g. traffic light status, traffic jam), scene motion patterns (e.g. vehicles making u-turns, east-west traffic and north-south traffic), etc. Most of the previous work used object tracks to model the scene. We propose a novel method for automatically discovering key motion patterns happening in a scene by observing the scene for an extended period. Our method does not rely on object detection and tracking, and uses low level features, the direction of pixel wise optical flow. We first divide the video into clips and estimate a sequence of flow-fields. Each moving pixel is quantized based on its location and motion direction. This is essentially a bag of words representation of clips. Once a bag of words representation is obtained, we proceed to the screening stage, using a measure called the ‘conditional entropy’. After obtaining useful words we apply Diffusion maps. Diffusion maps framework embeds the manifold points into a lower dimensional space while preserving the intrinsic local geometric structure. Finally, these useful words in lower dimensional space are clustered to discover key motion patterns. Diffusion map embedding involves diffusion time parameter which gives us ability to detect key motion patterns at different scales using multi-scale analysis. In addition, clips which are represented in terms of frequency of motion patterns can also be clustered to determine multiple dominant motion patterns which occur simultaneously, providing us further understanding of the scene.
|
Proposed Method Overview |
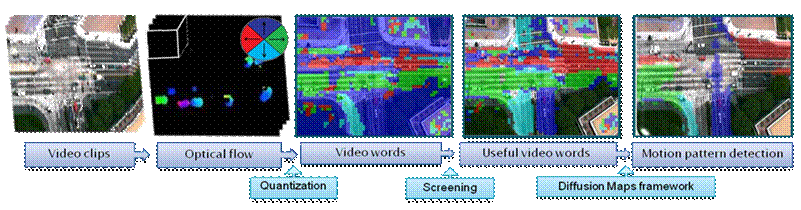
Above is the flowchart of our approach. To extract key motion patterns, we first extract low-level motion features through computing optical flow. These motion features are then quantized into video words based on their direction and location. Next, some video words are screened out based on the entropy over all clips for a given word. Key motion patterns are discovered automatically using diffusion maps embedding and clustering. |
Low-level Feature Quantization |
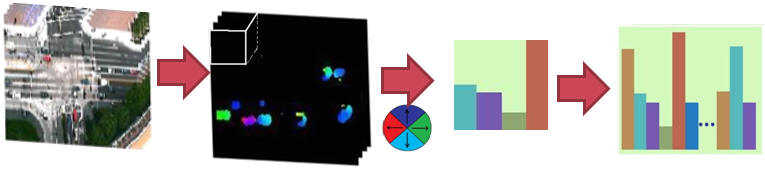 We estimate a sequence of flow-fields by dividing the long video into clips. The optical flow between two neighboring frames is computed with each pixel. A threshold on the optical flow magnitude of the pixels is used to remove pixels due to slight camera motion and variations in illumination. Each clip is split into spatiotemporal cuboids (3D patches of dimension NxNxL, where N by N patches at a given location in L frames of clips are used), and the motion of a moving pixel is quantized in four directions – North, South, East and West. For each cuboid in a clip, a 4 - bin histogram is computed. Each bin in a histogram of a given cuboid corresponds to one of the four motion directions at the location of the cuboid, and can be considered as a video word representing the clip. These local histograms for all cuboids in a clip are then concatenated into one long vector denoted by X. If the size of each image in a clip is (m x N) x (n x N), then the size of the vector X is m x n x 4 (m x n is the number of cuboids), where 4 represents the directions of motion of the pixels. Each bin of X is a codeword, resulting in a codebook of size m x n x 4. This is essentially a bag of words representation of clips. Each pixel is assigned a word from the codebook, which specifies a rough location and motion direction. |
Obtaining Useful Words |
|
The frequency of each video word in
different clips is summarized in a 2-D matrix (see figure 2).
This matrix is normalized to obtain probabilities. The
entropy over all clips for a given word is used as a measure to
determine which words (elements) in the bag (vector X) are
useful for motion pattern detection. The conditional entropy is
defined as |
Diffusion Maps Embedding |
|
First, we compute the Point-wise Mutual
Information (PMI) between the clips c and words w
using
The link between diffusion maps and distances can be summarized by the spectral identity
For detail, please see /projects/liujg/learning_semantic_vocabularies_dm.html. |
Experimental Results |
| 1. NGSIM dataset We choose one of the NGSIM videos, which is around 19 minutes long, 10 fps, 420x600 image size. We divided it into 224 clips, 5 seconds per clip. So the codebook size is 42x60x4. |
| a. Useful words
We show useful video words with 4 colors corresponding to four directions. The left one of each pair shows the words before screening and the right shows the useful words. Words with green, red, cyan and blue color correspond to vehicle movement from roughly west to east, east to west, north to south and south to north. Through this step, we discard most of the words which bring little information for key motion patterns detection in the video scene. Judging from the results, the screening method is meaningful and effective: Words in green and red (east, west direction) appear mostly on the east-west road; words in cyan and blue (north, south direction) appear mostly on the north-south road. However, there are still some words which are due to noise generated in optical flow that we cannot discard, due to the low resolution and low frame rate, and probably due to illumination changes in the NGSIM dataset. b. Motion patterns detection in low scale.
Figure 1
Figure 1 shows the automatic discovery of 20 motion patterns when t=2, σ=8. (1) — (9) are “horizontal” motion patterns. (1) and (3) are “vehicle moving through west-east road unhindered”. (4) and (6) correspond to “vehicle moving along east-west road to intersection and stopping”. (8) and (9) correspond to “vehicle proceeding after it stopped at the red traffic light”. (5) and (7) correspond to “vehicle stopping to wait for traffic light after crossing the intersection along east-west”. (10) and (11) correspond to “vehicle moving along north-south”. (12)— (19) correspond to “vehicle making left or right turn”. From the video, we find that the east-west road is crowded, whereas traffic flow of north-south road is small. This is consistent with our results since there are more east-west motion patterns compared to north-south. Also (17) shows that when vehicles from north-south make a right turn, there are always vehicles from south-north making a right turn at the same time. c. Motion patterns detection in high scales.
Above figure shows 3 of 10 patterns obtained by our method when t = 4, σ = 6, which are significantly different from the previous twenty. The pattern shown by cyan color (“vehicles going up north and vehicles in motion east-west, stopping to wait for light change, and some vehicles making right turn”) is essentially combination of (4), (6), (10), (13), (15) from Figure 1. The second pattern is combination of (12) and (18), and the third is the combination of (7) and (8) in Figure 1.
Three motion patterns are detected by our method when t = 8, and σ = 5. The first corresponds to major traffic which is in the north-south direction. The second corresponds to vehicle approaching from north and making a left turn. We noticed that this motion pattern is quite frequent in the video. The third motion pattern corresponds to east-west traffic. Through this multi-scale analysis, we verify that it is possible to embed high dimensional data into different levels by using diffusion time t. d. clip clustering based on main motion patterns
Here, we show the main motion patterns in 5 clusters of clips in NGSIM dataset. (1) crowded traffic in the east-west direction; (2) vehicle moving from north to south and the same time vehicle making right-turn form south to north; (3) vehicle moving from south to north, some making right-turn; (4) vehicle making left-turn; (5) light traffic in the east-west direction.
|
|
2. Crowd scene dataset The video is 1.5 hours video, 30fps, with variable number of motion patterns. Image size: 480x720. We divided it into 549 clips, 10 seconds per clip. The code book size 48x72x4. |
| a. Useful word
b. Motion patterns detection at low scale
Figure 2 30 motion patterns detected by our algorithm using t = 2, σ =10. (1)-(15) correspond to vehicle movement. (2) and (4) correspond to “vehicle moving along east-west road”, (5) corresponds to “vehicle moving along east-west road to intersection and stopping”. (1) and (3) correspond to “vehicle moving along west-east road and making left-turn”. (6-10) correspond to “vehicle moving along north-south road at different lanes” and (11-13) correspond to “vehicle crossing intersection from south to north”. (14-15) correspond to “vehicle making right turn from south to north”. (16)-(30) correspond to pedestrian movement. (16-19) correspond to “pedestrian crossing street on crosswalk from east to west”. (20)(21)(23)(24) correspond to “pedestrian crossing street on crosswalk from west to east”. (22)(25)(26-30) correspond to “pedestrian moving on pavement”. c. Motion patterns detection at high scales.
15 motion patterns detected using t=5, σ=10. Some multiple motion patterns in (a) merge into a single motion pattern in (b). (1) corresponds to “vehicle moving from east to west”. (7) corresponds to “vehicle moving from west to east”. (2)(4)(15) correspond to “vehicle moving along south-north road”. (8)(11) correspond to “vehicle crossing the intersection along north-south road”. (3) is the combination of (20)(21)(23)(25) in Figure 2, corresponds to “pedestrian crossing street from west to east on crosswalk”. (14) is the combination of (16)(17) in Figure 2, corresponds to “pedestrian crossing street from east to west on crosswalk”. (5)(6)(9)(10)(12)(13) correspond to “pedestrian movement”. d. Clip clustering based on main motion patterns
The main motion patterns in 6 clusters of clips. (1) vehicle moving on the north-south roads and at the same time some vehicles making right-turn form south to north; (2) vehicle moving on the east-west roads and some vehicles making left-turn form west to east; (3) crowded traffic in the east-west direction; (4) Vehicle and pedestrian moving from east to west; (5) pedestrian crossing road along east-west, meanwhile, vehicle from north-south road coming to the intersection and stopping; (6) vehicle moving from west to east, some of them making left-turn. Vehicle from north-south road coming and stopping.
|
Downloads
|