|
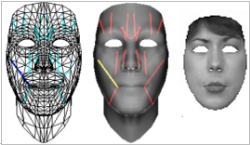
Estimation of rigid and non-rigid facial motion using anatomical face model |
We present a model-based
approach to recover the rigid and non-rigid facial
motion parameters in video sequences. Our face model is based on anatomically
motivated muscle actuator controls to model the articulated non-rigid
motion
of a human face. The model is capable of generating a variety of facial
expressions by using a small number of muscle actuator controls. We estimate
rigid and non-rigid parameters in two steps. First, we use a multi-resolution
scheme to recover the global 3D rotation and translation by linear least
square minimization. Then, we estimate the muscle actuator controls using
the
Levenberg-Marquardt minimization technique applied to a function, which
is
constrained by both optical flow and the dynamics of the deformable model.
We
present the results of our system on both real and synthetic images.
Associated
publications:
Alper
Yilmaz, Khurram Hassan Shafique; Estimation
of rigid and non-rigid facial motion using anatomical face model,
International Conference on Pattern Recognition, August 11-15 2002 - Québec
City Convention Center