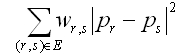Action Recognition Using Multiple Features
Related Publication: Jingen Liu, Saad Ali and Mubarak Shah, Recognizing Human Actions Using Multiple Features, IEEE International Conference on Computer Visiona and Pattern Recognition (CVPR), 2008. |
|
|
|
The fusion of multiple features is important for recognizing actions,
since a single feature based representation is not enough
to capture imaging variations (view-point, illumination etc.)
and attributes of individuals (size, age, gender etc.). We
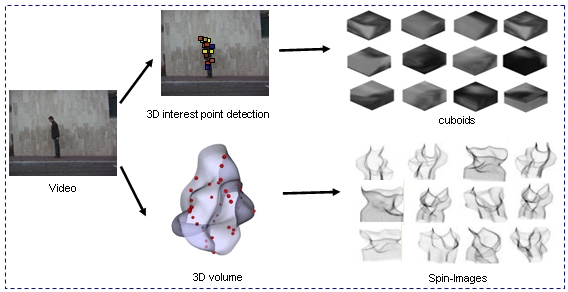
propose to use two types of features: The first feature is the
quantized vocabulary of local spatio-temporal (ST) volumes
(or cuboids) that are centered around 3D interest points in
the video. The second feature is a quantized vocabulary
of spin-images, which is aimed at capturing the 3D shape
of the actor by considering actions as 3D objects. To optimally
combine these features, we develop a mathematical
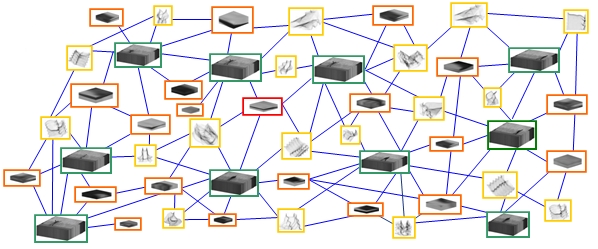
framework that treats different features as nodes in a
graph, where weighted edges between the nodes represent
the strength of the relationship between entities. The graph
is then embedded into a k-dimensional space, subject to
the criteria that similar nodes have Euclidian coordinates
which are closer to each other. This is achieved by converting
this constraint into a minimization problem whose solution
is the eigenvectors of the graph Laplacian matrix. The
embedding into a common space allows the discovery of
relationships among features by using Euclidian distances.
The performance of the proposed framework is tested on
publicly available data sets. The results demonstrate that
fusion of multiple features help in achieving improved performance.
|
|
|
1. Generating multiple features
|
2. Building a Laplacian Graph for embedding
- Video, Spatiotemporal features, Spin-Image features are nodes of a monolithic graph
- •Edges encode coarse similarity measures.
- •Embed this graph in a common k-dimensional space and find latent relationships.
- •Fiedler Embedding
|
|
|
|
Intuition
- Semantically similar vertices have strong intrinsic relationship.
- Geometrically, those vertices are located on a manifold which embedded in a higher dimension space
- Place the vertices into a k-dimensional space s.t. the distance between two vertices can be devalued by the Euclidian distance.
Suppose, p_{r} and p_{s} are the locations of the vertices in the k-dimensional space, then we need to minimize:
where w_{r,s}: weight between two nodes.
Represent the positions of the n nodes in a matrix
Now, we can verify the minization problem is
with contrains:
|
|
|
Spatiotemporal Features |
1. Apply two separate linear filters respectively to spatial and temporal dimensions as follows,
2. Apply PCA to gradient based descriptor to lower dimension.
3. Quantize the features into video-words.
4. Some examples of video-words.
|
Spin-image Features |
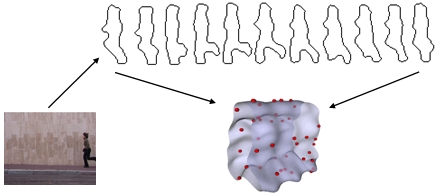
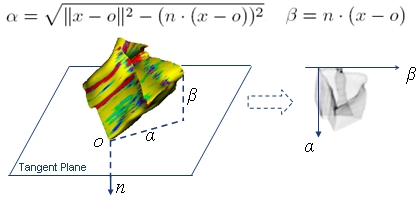
1. Create Action Volume from contours.
2. Generate Spin-images from the action volume
Four elements: the orientated point O, the tangent plane to O, surface points index (alpha, beta).
3. Bag of Spin-Image features
- Apply PCA to reduce the dimensionality of the spin-images.
-
Using k-means to quantize the spin-image features. A cluster of
spin-images is taken as a video-word
- An action is represented by a bag of spin-image video-words.
|
|
|
We applied our method on nine-action dataset and IXMAS multiple view dataset. |
-
Nine actions performed by 9 actors, total 82 video sequences
Bend, Jack, Jump, PJump, Run, Side walk, Walk, One hand wave (wave1), two hand wave (wave2)
- 200 interest cuboids extracted from each video with sigma =1, and tao=2.
- Codebook size is 200 and 1,000
- Leave one out cross validation scheme
|
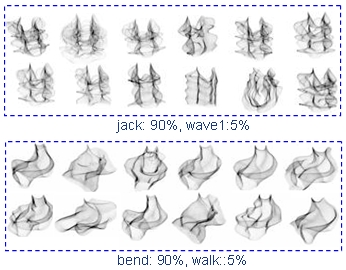
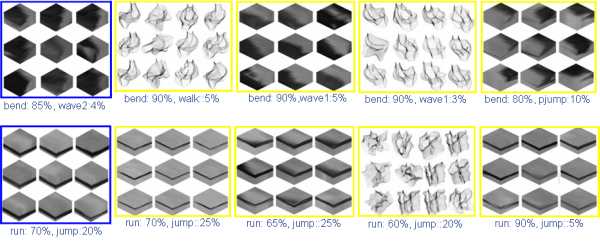
1. Qualitative Results |
a. Query action videos by spin-image features
b.Query action by ST features
c. Query features by ST feature
d. Query features by spin-image feature
e.Query features by action video
|
| 2. Quantitative results |
|
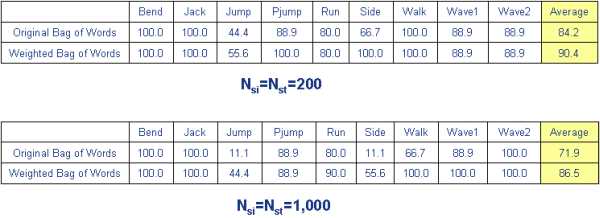
1) Comparison of original bag of words method and our our weighted bag of words method
-
Goal: meaningful group can help the classification
-
Suppose the original histogram 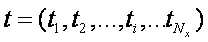
-
The weighted feature frequency of term i can be, 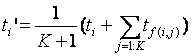
-
where f(i,j) is a function which returns the j-th nearest neighbors of the feature i.
-
|
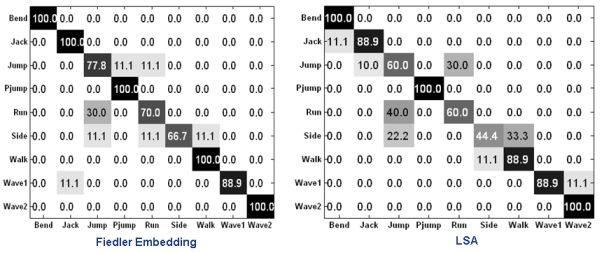
2) Comparison of Fiedler Embedding (unlinear method) with LSA (linear method)
|
3) Contribution of different features towards classification
|
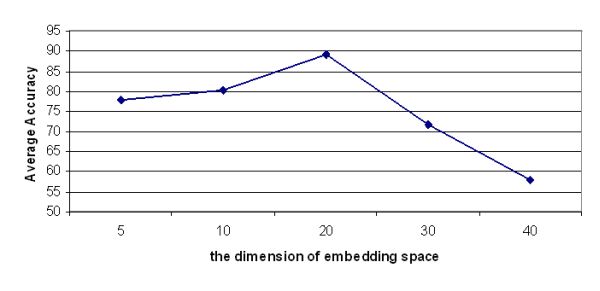
4) The variation of embedding dimension affects the performance
|
3. Experiment Results on IXMAS multiple view dataset
- From each video, 200 cuboids are extracted
- 1,000 video-words
- 6-fold CV scheme, namely 10 videos of actors for learning and the rest for testing.
- Our approach does not require 3D construction,
|
1) Action Volume (Checking watch)
|
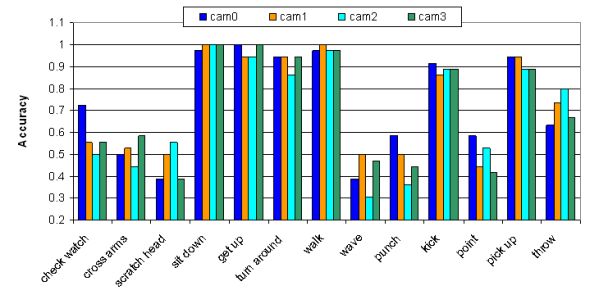
2) Learning from four views and testing with single views ( with different features)
|
3) Learning from four views and recognizing with single view in detail
|
4) Learning from four views and testing on four views (confusion table)
|
|
- Power Point Presentation
- Poster
|