Please visit the new CRCV | Center for Research in Computer Vision web site here!
Featured Projects
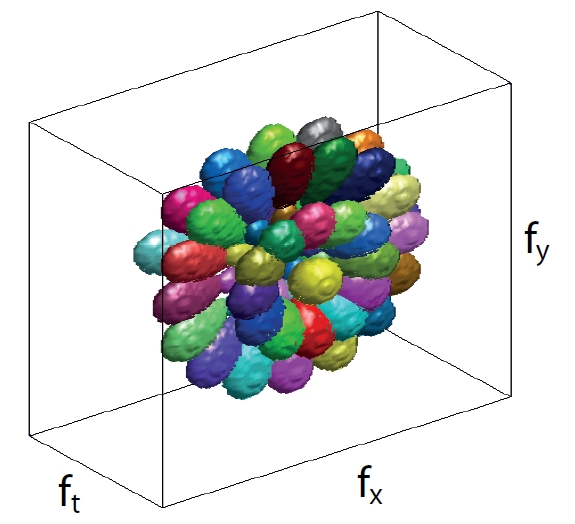
Classifying Web Videos using a Global Video Descriptor
Computing descriptors for videos is a crucial task in computer vision. In this work, we propose a global video descriptor for classification of realistic videos as the ones in Figure 1. Our method, bypasses the detection of interest points, the extraction of local video descriptors and the quantization of descriptors into a code book; it represents each video sequence as a single feature vector. Our global descriptor is computed by applying a bank of 3-D spatiotemporal filters on the frequency spectrum of a video sequence, hence it integrates the information about the motion and scene structure. We tested our approach on three datasets, KTH, UCF50 and HMDB51. Our global descriptor obtained the highest classification accuracies on two of the most complex datasets UCF50 and HMDB51 among all published results, which demonstrates the discriminative power of our global video descriptor for classifying videos of various actions. In addition, the combination of our global descriptor and a state-of-the-art local descriptor resulted in a further improvement in the results.
Reference:
Berkan Solmaz, Shayan Modiri Assari and Mubarak Shah
"Classifying Web Videos using a Global Video Descriptor", Machine Vision and Applications (MVA), 2012.
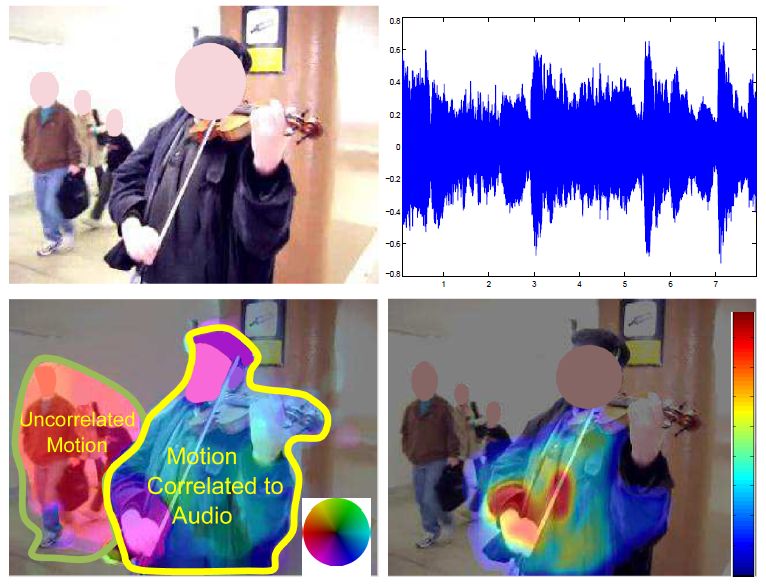
Audio source localization and audio-visual synchronization using CCA
We propose a novel method that exploits correlation between audio-visual dynamics of a video to segment and localize objects that are the dominant source of audio. Our approach consists of a two-step spatiotemporal segmentation mechanism that relies on velocity and acceleration of moving objects as visual features. Each frame of the video is segmented into regions based on motion and appearance cues using the QuickShift algorithm, which are then clustered over time using K-means, so as to obtain a spatiotemporal video segmentation. The video is represented by motion features computed over individual segments. The Mel-Frequency Cepstral Coefficients (MFCC) of the audio signal, and their first order derivatives are exploited to represent audio. The proposed framework assumes there is a non-trivial correlation between these audio features and the velocity and acceleration of the moving and sounding objects. The canonical correlation analysis (CCA) is utilized to identify the moving objects which are most correlated to the audio signal. In addition to moving-sounding object identification, the same framework is also exploited to solve the problem of audio-video synchronization, and is used to aid interactive segmentation. We evaluate the performance of our proposed method on challenging videos. Our experiments demonstrate significant increase in performance over the state-of-the-art both qualitatively and quantitatively, and validate the feasibility and superiority of our approach.
Reference:
Hamid Izadinia, Irman Saleemi and Mubarak Shah
"Multimodal Analysis for Identification and Segmentation of Moving-Sounding Objects", IEEE Transactions on Multimedia, 2012.
Simultaneous Video Stabilization and Moving Object Detection in Turbulence
Turbulence mitigation refers to the stabilization of videos with non-uniform deformations due to the influence of optical turbulence. Typical approaches for turbulence mitigation follow averaging or de-warping techniques. Although these methods can reduce the turbulence, they distort the independently moving objects which can often be of great interest. In this paper, we address the novel problem of simultaneous turbulence mitigation and moving object detection. We propose a novel threeterm low-rank matrix decomposition approach in which we decompose the turbulence sequence into three components: the background, the turbulence, and the object.

Reference:
Omar Oreifej, Xin Li, and Mubarak Shah
"Simultaneous Video Stabilization and Moving Object Detection in Turbulence", IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 2012.
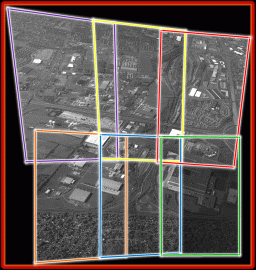
Motion Analysis on CLIF Dataset
The problem that this project deals with is that of detection and tracking of large number of objects in Wide Area Surveillance (or WAS) data. WAS is aerial data that is characterized by a very large field of view. The particular dataset that we used for this project is the CLIF dataset. CLIF stands for Columbus Large Image Format, the dataset is available here.
Reference:
Vladimir Reilly, Haroon Idrees and Mubarak Shah
"Detection and Tracking of Large Number of Targets in Wide Area Surveillance", ECCV 2010