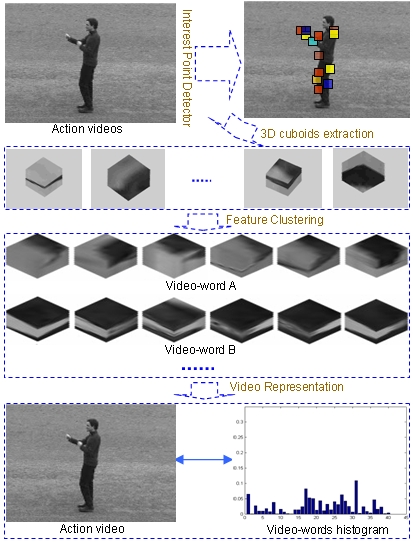
Learning Human Actions via Information Maximization
Related Publication:
Jingen Liu and Mubarak Shah, Learning Human Actions via Information Maximization, IEEE International Conference on Computer Vision and Pattern Recognition(CVPR), 2008.
|
|
|
We present a novel approach for automatically
learning a compact and yet discriminative
appearance-based human action model. A video sequence
is represented by a bag of spatiotemporal features called
video-words by quantizing the extracted 3D interest points
(cuboids) from the videos. Our proposed approach is able
to automatically discover the optimal number of videoword
clusters by utilizing Maximization of Mutual Information(
MMI). Unlike the k-means algorithm, which is typically
used to cluster spatiotemporal cuboids into video
words based on their appearance similarity, MMI clustering
further groups the video-words, which are highly correlated
to some group of actions. To capture the structural
information of the learnt optimal video-word clusters, we
explore the correlation of the compact video-word clusters.
We use the modified correlgoram, which is not only translation
and rotation invariant, but also somewhat scale invariant.
We extensively test our proposed approach on two
publicly available challenging datasets: the KTH dataset
and IXMAS multiview dataset. To the best of our knowledge,
we are the first to try the bag of video-words related
approach on the multiview dataset. We have obtained very
impressive results on both datasets.
|
|
There
are three steps in bag of video-words modeling. First, detect 3D
interest points; Second, extract cuboids surrounding the interest point
and compute the corresponding descriptor. Third, group the cuiboids
(descriptors) into video-words. Finally, represent the entire video by
the histogram of the video-words.
|
- How large of codebook size can achieve good performance?
-
In this project, we can automatically find the optimal number of
video-word-clusters by using information maximization approach.
- Can video-words be further grouped into semantically similar video-word-clusters?
- Due
to Mutual Information being used for further grouping in our project,
the new video-word-clusters are able to capture some semantical meaning
of the video-words.
- How to integrate structure (spatial and/or temporal) information into orderless bag of video-words model?
- We explored two approaches: Spatial Correlogram and Spatiotemporal Pyramid Matching.
|
|
We define Mutual Information between X (video-words) and Y (action videos) as follows,
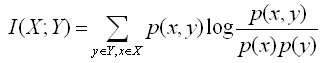
Then, given a mapping 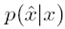 , the objective function of the clustering is defined as follows, , the objective function of the clustering is defined as follows,
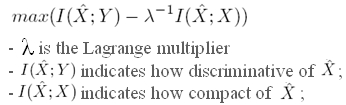
Therefore, we are looking for a cluster which has the better tradeoff between discimination and compactness.
|
- Start with the trival partition. It means each video-word is a single cluster;
- Greedily
merge two components which makes the loss of mutual information is
minimized. The loss of mutual information due to the merge of two
components can be expressed as,
- The breef steps are showed as follows,
|
|
|
The KTH dataset is a wildly used action dataset which has 6 actions with almost 600 videos performed by 25 people.
|
1. The classification performance comparison between the initial
codebook and the optimized codebook under different initial codebook
sizes. |
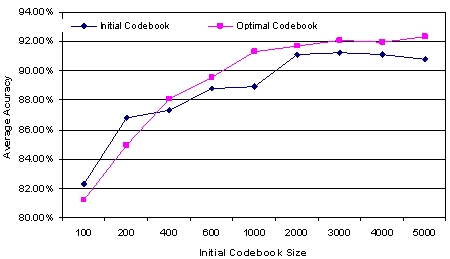 |
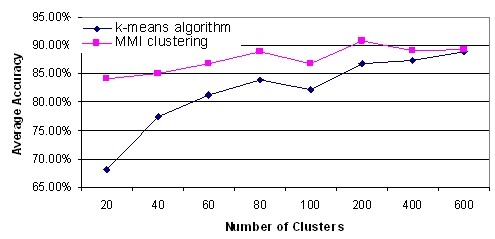
2. The performance comparison between using MMI clustering and directly apply k-means algorithm.
>> MMI clustering reduces the initial dimension of 1,000 to the corresponding number.
>> MMI discovered the Nc=177 as the optimal number of VWCs with average accuracy 91.3%.
|
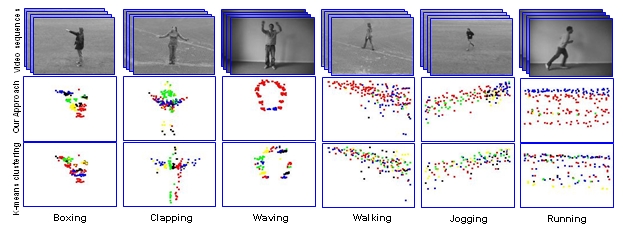
3. The importance of the video-words clusters and their structural information
The
first row shows the examples of six actions. The following tow rows
respectively demonstrate the distribution of the optimal 20 video-words
clusters using our approach and 20 video-words using k-means. We
superimpose the 3D interest points in all frames into one image.
Different clusters are represented by different color codes. Note that
our model is more compact e.g. see "waving" and "running" actions
|
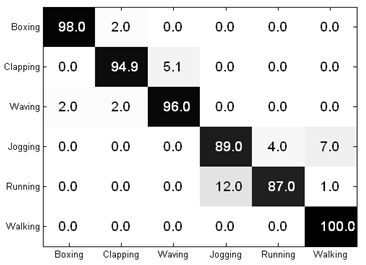
4. Spatial correlogram
Given
P_{i} as cuboids, l_{i} as labels and D_{i} as quantized distance, the
spatial correlogram can be defined as a probability,
We show the confusion table of the performance of the video-word-cluster correlogram as follows,
The number of VWC is
60, and 3 quantized distances are used (average accuracy is 94.15%).
|
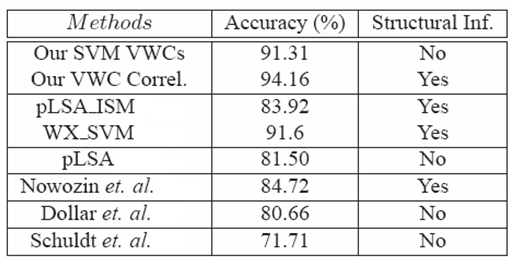
5. The performance of the different bag of video-words related approaches.
|
|
|
We
picked up 4 views and 13 actions acted by 12 actors (The top view was
not included in our experiments). We show some examples in the
following picture.
|
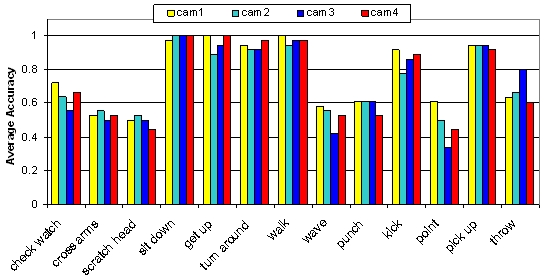
1. The performance of learning with four views, while test on single view
The
189 video-word-clusters are learned from 1,000 video-words. The
performance is better than Weinland's ICCV 2007 result, which is {65.4,
70.0, 54.3, 66.0} %. Besides, their method requirs 3D reconstruction.
The following figure gives the detail classification performance of
each view.
|
2. the performance of learning from three views, and test on the rest view.
|
|
- Paper
- Power Point Presentation
- Poster
|