|
Geometric Constraints for Human Detection in Aerial
Imagery Related Publication: Vladimir Reilly, Berkan Solmaz and Mubarak Shah, Geometric Constraints for Human Detection in Aerial Imagery, The 11th European Conference on Computer Vision (ECCV), 2010. |
|
|
Introduction |
Ground-Plane Normal and Shadow Constraints |
|
Metadata The imagery obtained from the UAV has the following metadata associated with most of the frames. It has a set of aircraft parameters latitude, longitude, altitude, which define the position of the aircraft in the world, as well as pitch, yaw, roll which define the orientation of the aircraft within the world. Metadata also contains a set of camera parameters scan, elevation, twist which define the rotation of the camera with respect to the aircraft, as well as focal length, and time. We use this information to derive a set of world constraints, and then project them into the original image. World Constraints We employ three world constraints.
Given latitude, longitude, and time, we obtain the position of the sun relative to the observer on the ground. It is defined by the azimuth angle (from the north direction), and the zenith angle (from the vertical direction). Having an assumption for the height of the person in the world, we find the length of the shadow using the zenith angle of the sun. Using the azimuth angle, we find the groundplane projection of the vector pointing to the sun. Image Constraints Before we can use our world constraints for human detection, we have to transform them from the world coordinates to the image coordinates. To do this we use the metadata to obtain the projective homography transformation that relates image coordinates to the ground plane coordinates. In addition, we compute the ratio between the projected shadow length and the projected person height.
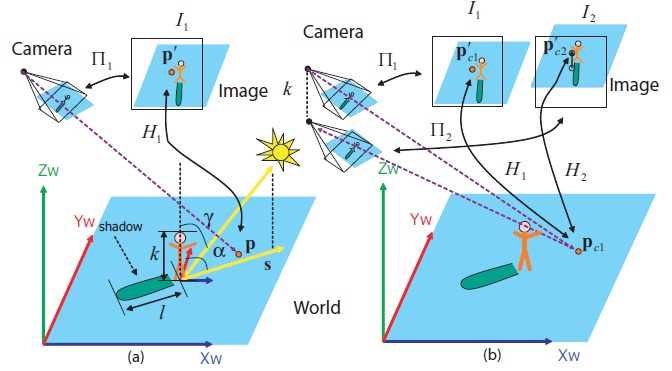
Figure 2. Left, the sensor model П1 maps points in camera coordinates into world coordinates (since the transformation between image and camera coordinates is trivial we do not show it in the image). X corresponds to East direction, Y to North, Z to vertical direction. Vector S is pointing from an observer towards the sun along the ground. It is defined in terms of α azimuth angle between northern direction and the sun. Zenith angle Ɣ is between vertical direction and the sun. The height of a human is k, and the length of the shadow is l. We place the image plane into the world, and raytrace through it to find the world coordinates of the image points (we project from the image plane to the ground plane). We compute a homography H1 between image points and their corresponding world coordinates on groundplane. Right, illustrates how we obtain the projection of the groundplane normal in the original image. Using a lowered sensor model П2 we obtain another homography H2, which maps points in camera coordinates to a plane above the ground plane. Mapping a world point pc1 using H1, and H2, gives two image points p'c1, and p'c2. Vector from p'c1 to p'c2 is the projection of the normal vector. |
Human Detection |
|
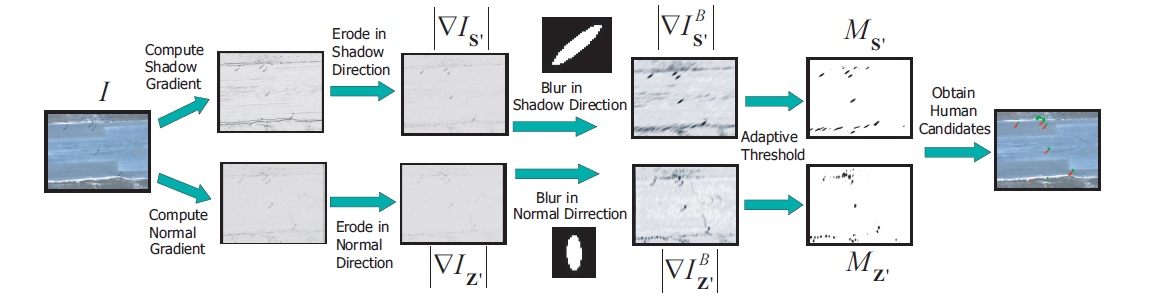
In order to avoid the search over the entire frame, the first step in our human detection process is to constrain the search space of potential human candidates. We define the search space as a set of blobs oriented in direction of shadow, and direction of normal. To do so we utilize the image projection of the world constraints derived previously - the projected orientation of the normal to the ground plane, the projected orientation of the shadow, and the ratio between the projected person height, and projected shadow length. See Figure 3.
Figure 3. This figure illustrates the pipeline of applying image constraints to obtain an initial set of human candidates. Our next step is to relate the shadow and human blob maps, and to remove shadow-human configurations that do not satisfy the image geometry which we derived from the metadata. We search every shadow blob, and try to pair it up with a potential object blob, if the shadow blob fails to match any object blobs, it is removed. If an object blob never gets assigned to a shadow blob it is also removed.
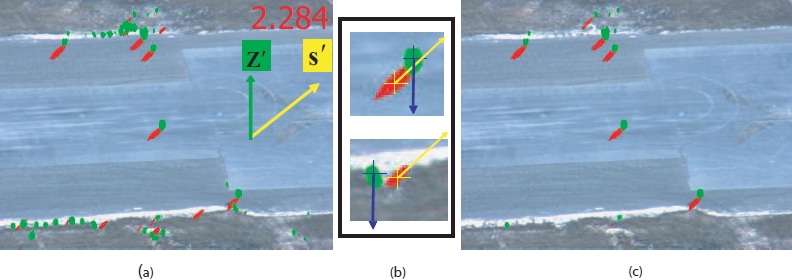
Figure 4. (a) shows shadow blob map (shown in red), and normal blob map (shown in green), overlaid on the original image. Notice there are false detections at the bottom of the image. Yellow arrow is the projected sun vector S', the projected normal vector z' is shown in green, and the ratio between the projected normal and shadow lengths is 2.284 (b) shows example candidates being refined. A valid configuration of human and shadow blobs (top) results in an intersection of the rays, and is kept as a human candidate. An invalid configuration of blobs (bottom) results in the divergence of the rays, and is removed from the set of human candidates. (c) shows refined blob maps after each normal blob was related to its corresponding shadow blob.
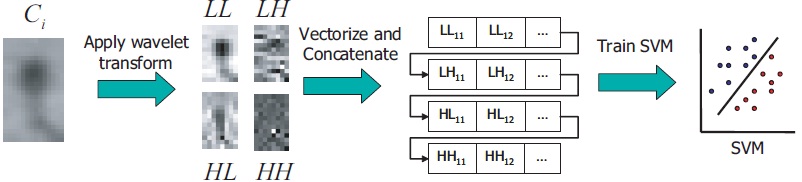
Wavelets have been shown to be useful in extracting distinguishing features from imagery. So in the final step of our method, we classify each object candidate as either a human or non-human using a combination of wavelet features and SVM (Figure 5). We chose wavelet features over HOG because we obtained higher classification rate on a validation set. We suspect that this is due to the fact that in the case of HOG, the small size of chips does not allow for the use of optimal overlapping grid parameters, giving too coarse sampling. We apply Daubechies 2 wavelet filter to each chip.
Figure 5. Object candidate classification pipeline. Four wavelet filters (LL, LH, HL, HH) produce scaled version of original image, as well as gradient like features in horizontal vertical and diagonal directions. The resulting outputs are vectorized, normalized, and concatenated to form a feature vector. These feature vectors are classified using SVM. |
|
|
Experimental Results |
|
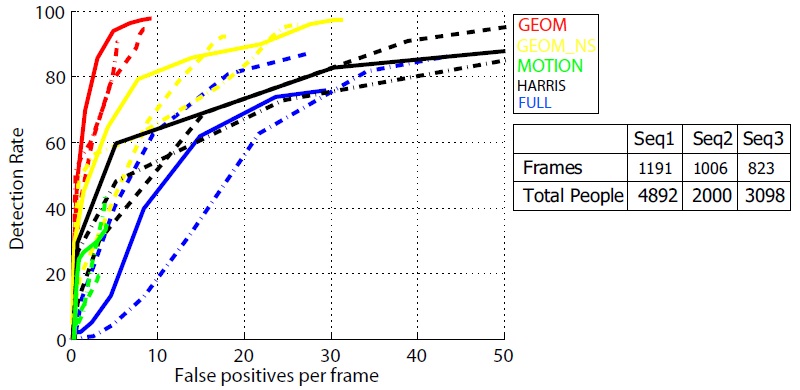
Qualitative evaluation is done on sequences from VIVID3 and 4 as well as some of our own data. The data contains both stationary and moving vehicles and people, as well as various clutter in the case of VIVID4. Vehicles cast a shadow, and are usually detected as candidates, these are currently filtered out in the classification stage. For quantitative evaluation we evaluated our detection methods on three sequences from the DARPA VIVID3 dataset of 640x480 resolution, and compared the detection against manually obtained groundtruth. We used the Recall vs False Positives Per Frame (FPPF) evaluation criteria. To evaluate the accuracy of the geometry based human candidate detector method, we require the centroid of the object candidate blob to be within w pixels of the centroid blob, where w is 15. Figure 6 compares ROC curves for our geometry based method with and without the use of object-shadow relationship refinement, and centroid localization, conventional full frame detection method, and standard motion detection pipeline of registration, detection, and tracking. Figure 7 shows qualitative detection results.
Figure 6. SVM confidence ROC curves for sequences 1 (dashed-dotted), 2 (dashed), and 3 (solid). Our Geometry based method with shadow, object-shadow relationship refinement, and centroid localization is shown in red. Yellow curves are for our geometry based method without the use of object-shadow relationship refinement, or centroid localization. A standard full frame detector (HOG) is shown in blue. Green shows results obtained from classifying blobs obtained through registration, motion, detection, and tracking. Black curves are for our modified implementation of [1], which uses Harris corner tracks.
Figure 7. (a) (b) and (c) compare motion detection (top row), and our geometry based method (bottom row). (a) Human is stationary and was not detected by the motion detector. (b) Moving blob includes shadow, the centroid of blob is not on the person. (c) Two moving blobs were merged by the tracker because of shadow overlap, centroid is not on either person. By contrast our method correctly detected and localized the human candidate (green). (d) and (e) compare geometry constrained human detection, and full frame HOG detection. Human candidates that were discarded by the wavelet classifier as clutter are shown in magenta, candidates that were classified as human are shown in black. Unconstrained full frame detection (e) generates many false positives.
|
Downloads
|
|
References [1] Miller, A., Babenko, P., Hu, M., Shah, M.: Person tracking in UAV video. CLEAR (2007)
|