Recognizing Realistic Actions from Videos "in the Wild"
Related Publication:
Jingen Liu, Jiebo Luo and Mubarak Shah, Recognizing Realistic Actions from Videos "in the Wild", IEEE International Conference on Computer Vision and Pattern Recognition(CVPR), 2009.
|
|
|
In
this paper, we present a systematic framework for recognizing realistic
actions from videos “in the wild.” Such unconstrained videos are
abundant in personal collections as well as on the web. Recognizing
action from such videos has not been addressed extensively, primarily
due to the tremendous variations that result from camera motion,
background clutter, changes in object appearance, and scale, etc. The
main challenge is how to extract reliable and informative features from
the unconstrained videos. We extract both motion and static features
from the videos. Since the raw features of both types are dense yet
noisy, we propose strategies to prune these features. We use motion
statistics to acquire stable motion features and clean static features.
Furthermore, PageRank is used to mine the most informative static
features. In order to further construct compact yet discriminative
visual vocabularies, a divisive information-theoretic algorithm is
employed to group semantically related features. Finally, AdaBoost is
chosen to integrate all the heterogeneous yet complementary features
for recognition. We have tested the framework on the KTH dataset and
our own dataset consisting of 11 categories of actions collected from
YouTube and personal videos, and have obtained impressive results for
action recognition and action localization.
|
- Recognizing
realistic actions from unconstrained videos, such as personal videos,
TV news videos, web videos (YouTube videos), etc.
- Mining bags of informative hybrid features
- Obtain good motion features by motion statistics
- Acquire informative static features by motion statistics and PageRank
- Construct semantic visual vocabulary
- Boost heterogeneous features
- Performing
action recognition without explicitly detecting and tracking subject or
its joints, because of our feature mining strategies
|
|
We
collected 11 realistic action categories from YouTube with about 1,600
videos in total. For the details of this dataset, please click here.

- Challenges
in unconstrained videos: large variations in camera motion, object
appearance and pose, object scale, viewpoint, cluttered background,
illumination conditions, etc.
|
|

- Features Extraction
- Motion
feature: apply two separated filters on the input video, i.e. Gassian
filter on space dimension and 1D Gabor filter on time dimension; apply
PCA to reduce the dimension of the gradient-based feature descriptor.
- Static
feature: apply three types of feature detector on the sampled frames:
Harris-Laplacian, Hessian-Laplacian, and MSER detectors ; represent
them by SIFT descriptor.
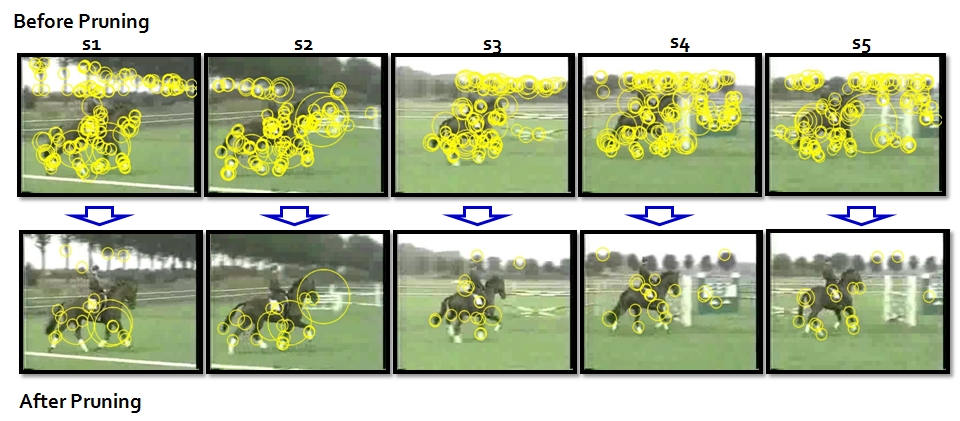
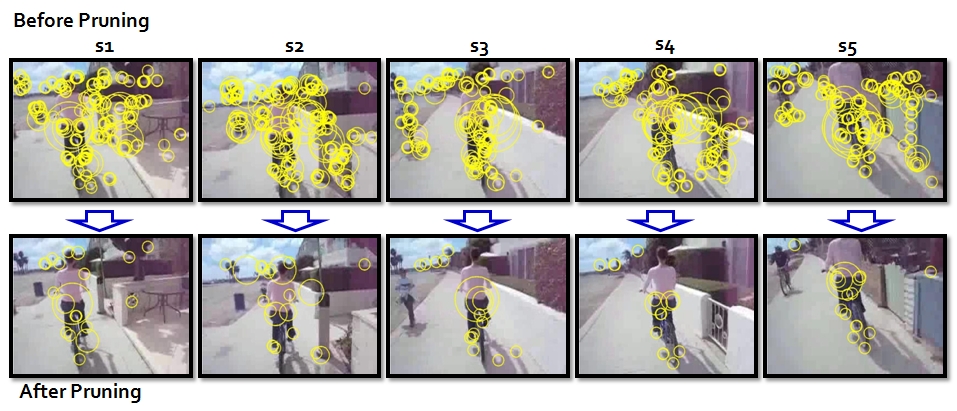
- Motion feature pruning by motion statistics.
- Static feature pruning by motion statistics and PageRank technique.
- Apply information-theoretic divisive algorithm to obtain discriminative yet compact vocabularies.
- Select good motion and static features by boosting.
|
- Remove abrupt camera motion.
- Compute
histogram of number of motion features at each frame, remove the frames
which contain much more number of features than the average.
- Estimate good features using neighborhood information

|
- Why static features?
Static feature can be treated as the complementary feature of motion.
- Local shape context of key poses is useful for recognition, as the "boxing" and "clapping" actions in KTH dataset.
- In
unconstrained videos, the correlated object appearance is useful for
recognition, such as "horse" in "horseback riding", "racket" in "tennis
playing", etc.
- Unlike motion features that
may be unrelieable due to camera motion, the detection and extraction
of static features are not affected by the camera motion.
- Why
not global context? As the following "soccer juggling" demonstrates,
the background (global context) is very diverse even for the videos of
same action, as for the unconstrained videos.

Therefore,
we want to select informative features from the foreground as the
highlight in the following "walking dog" sequences. 
- Estimate Regions of Interest by using motion statistics
- Using PageRank to obtain consistent features from the foreground.
- Subject and camera moving left
- Subject and camera moving right
- Camera following subject from behind
|
- Information-theoretic divisive algorithm
|
|
|
The KTH dataset is a wildly used action dataset which has 6 actions with almost 600 videos performed by 25 people.
|
To verify the effect of hybrid of motion and static features on KTH dataset. |
|
|
|
1. The effect of motion feature pruning
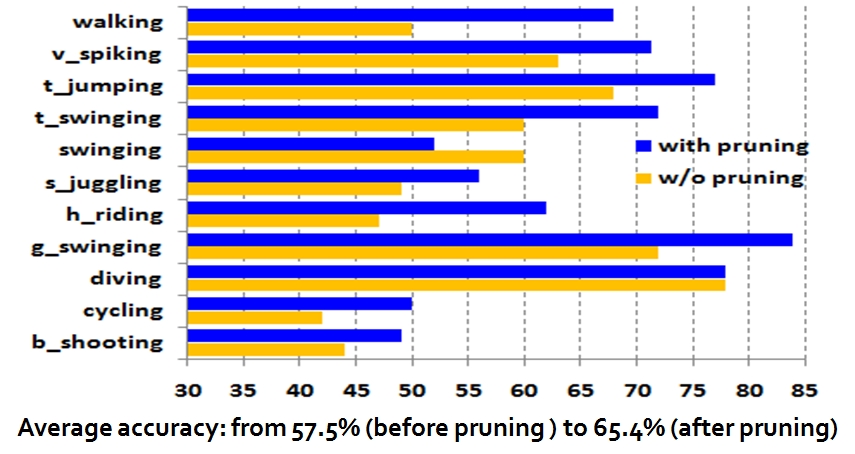
|
2. The effect of static feature pruning
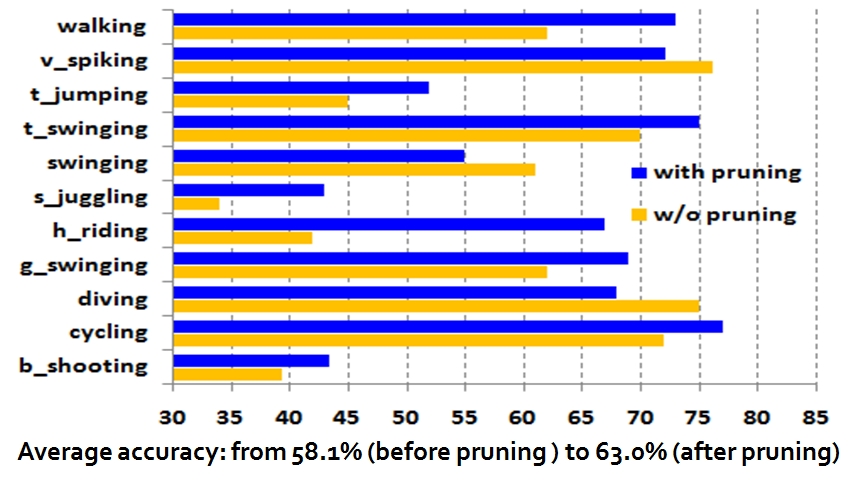
|
3. the effect of hybrid of motion and static features.
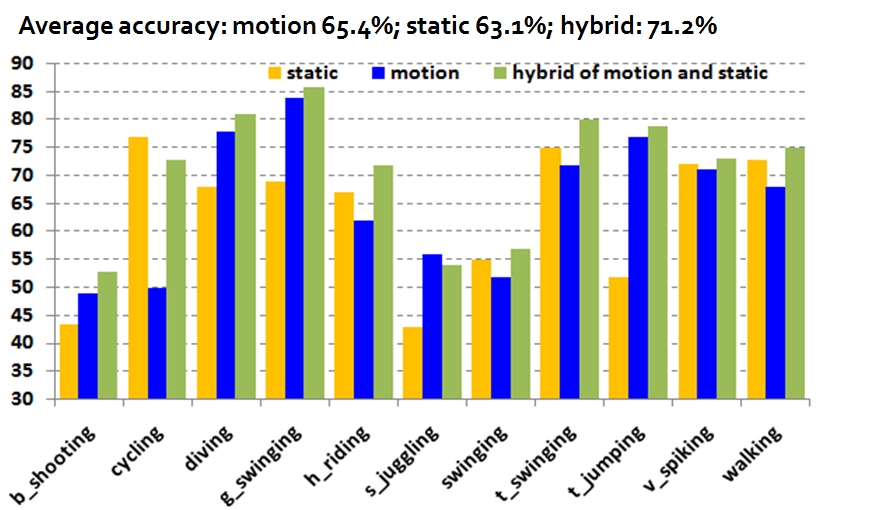
|
3. some recognition results with localization.
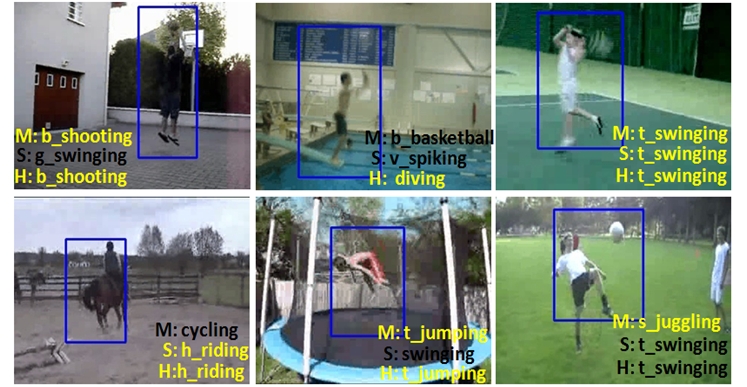
"M","S"
and "H" in the images means the following judgements are made on the
"motion", "static", "hybrid of motion and static" features,
respectively. |
|
|
- Paper
- Power Point Presentation
- YouTube Action Dataset
|